Updated March 23, 2023

Introduction to Supervised Machine Learning Algorithms
Supervised Machine Learning is defined as the subfield of machine learning techniques in which we used labelled datasets for training the model, making predictions of the output values and comparing its output with the intended, correct output, and then compute the errors to modify the model accordingly. Also, as the system is trained enough using this learning method, it becomes capable enough to provide the target values from any new input.
It has been classified into 3 categories based upon their learning method i.e.
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
In this article, we will study Supervised learning and see its different types of learning algorithms.
Supervised Learning Algorithms
When we train the algorithm by providing the labels explicitly, it is known as supervised learning. This type of algorithm uses the available dataset to train the model. The model is of the following form.
Y=f(X) where x is the input variable, y is the output variable, and f(X) is the hypothesis.
The objective of Supervised Machine Learning Algorithms is to find the hypothesis as approx. as possible so that when there is new input data, the output y can be predicted. The application of supervised machine learning is to predict whether a mail is spam or not spam or face unlock in your smartphone.
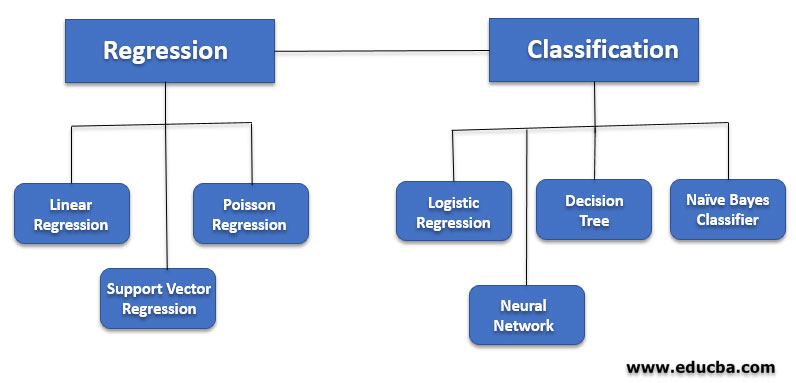
Types of Supervised Machine Learning Algorithm
Supervised Machine Learning is divided into two parts based upon their output:
- Regression
- Classification
1. Regression
In Regression the output variable is numerical(continuous) i.e. we train the hypothesis(f(x)) in a way to get continuous output(y) for the input data(x). Since the output is informed of the real number, the regression technique is used in the prediction of quantities, size, values, etc.
For Example, we can use it to predict the price of the house given the dataset containing the features of the house like area, floor, etc.
A few popular Regression Algorithm is:
- Linear Regression
- Support Vector Regression
- Poisson Regression
a. Linear Regression
The simplest form of regression algorithm. In this, we have two variables; one is independent, i.e. the predicted output, and the other is dependent, which is the feature. The relationship between these two variables is assumed to be linear, i.e. straight line can be used to separate them. The objective of this function is to get the line that divides these two variables by keeping the error as less as possible. The error is the sum of the Euclidean distance between points and the line.
When it has only one independent variable, then it is termed as simple linear regression and is given by:
![]()
While when it has more than one independent variable, it is termed as multiple linear regression. And is given by
![]()
In both, the above equation y is the dependent variable while x is the independent variable.
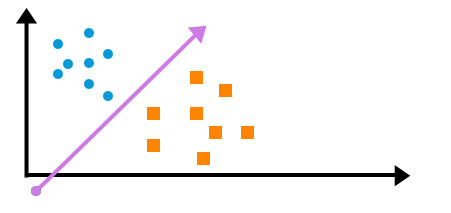
b. Support Vector Machine
It is a classification algorithm. In the support vector machine, we use a hyperplane to classify the dependent variable when we have only two dependent variables, i.e. only two classes to predict; then, this hyperplane is nothing but a straight line.
The objective of SVM is to get the hyperplane in a way that all the independent variables of one class should be on one side. An optimal SVM function will result in a hyperplane that is at an equal distance from both the class.
c. Poisson Regression
It works on the principle of Poisson distribution, Due to which the value of the dependent variable(y) is a small, non-negative integer like 0,1,2,3,4 and so on. Assuming that a large count won’t happen frequently. Due to this fact, the Poisson regression is similar to logistic regression, but the dependent variable is not limited to a specific value.
2. Classification
In classification, the output variable is discrete. i.e. we train the hypothesis(f(x)) in a way to get discrete output(y) for the input data(x). The output can also be termed as a class. For example, by taking the above example of house price, we can use classification to predict whether the house price will be above or below instead of getting the exact value. So we have two classes, one if the price is above and the other if it is below.
Classification is used in speech recognition, image classification, NLP, etc.
Few Popular Classification Algorithm is:
- Logistic Regression
- Neural Network
- Decision Tree
- Naïve Bayes Classifier
a. Logistic Regression
It is a type of classification algorithm. It is used to estimate the discrete value based upon the given independent variables. It helps in determining the probability of the occurrence of a function by using a logit function. Output(y) of the hypothesis of these techniques lies between 0 to 1.
A function used in logistic regression is given by :
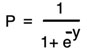
where y is the equation on line. Due to this function, the value is scaled between 0 to 1. This function is also termed as a sigmoid function.
b. Neural Network
The neural network is a classification algorithm that has a minimum of 3 layers. Input – Hidden – Output.
The number of hidden layers may vary based upon the application of the problem. Each hidden layer tries to detect a pattern on the input. As the pattern is detected, it gets forwarded to the other hidden layer in the network till the output layer. Please see the figure below.
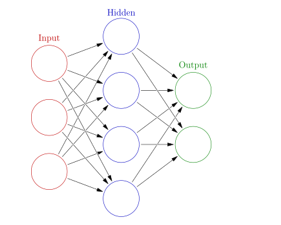
The circle in the figure determines the neuron which stores the features (only in the input layer), i.e. the independent variable.
Suppose we have a 32×32 image of a number, then in order to classify the number, we can use a neural network. We will pass the images to the input layers. Since the number of pixels in the image is 32×32 = 1024, we will have 1024 neurons in the input layers. The number of neurons in hidden layers can be tweaked, but for the output layer, it has to be 10 since, in this example, the number can be anything between 0-9.
The node of the output layers contains the probability. Whichever node has the highest probability that the node is supposed to be the resultant class?
c. Decision Tree
The decision tree got its name from the fact that it builds classification or regression models in the form of tree structures. It breaks down the dataset into a smaller subset and associate decision with it. As a result, we get a tree with decision nodes and leaf nodes. A decision node can have two or more branches and will lead you to the leaf nodes. A leaf node is used to represent the classification or decision. It uses the if-then-else decision rule to approximate the result. The deeper we go down in the tree, the more complex its rules will become, which will also result in the fitter model.
d. Naïve Bayes Classifiers
Naïve base is a collection of classification algorithms, I.e. based on Bayes theorem. They all work on the same principle, i.e. none of the features is dependent on each other. Let us see how the learning model for it will look like. Suppose we have to perform prediction using two features A, B i.e. P(A, B), then we can write it as
P(A, B) = P(A)P(B) since both are independent of each other.
Hence, we can say that:
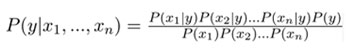
Which can be written as:
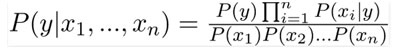
Since the denominator will remain constant, we can remove it so we get
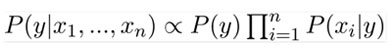
Finally, we just need a classification model. The above equation will give the probability for each class. We just need to get the class with max probability. Hence y will be:
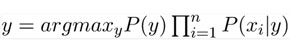
Hence this classification model can be used for the prediction of class. Note that P(y) is the probability of the class while P(xi | y ) is the conditional probability
Conclusion
In this article, we got an idea of a supervised learning algorithm with its type and different algorithm. Though there is numerous another algorithm that needs to be discussed but Having an idea of all these above algorithms will help you in kick start of your journey in machine learning.
Recommended Articles
This is a guide to Supervised Machine Learning Algorithms. Here we discuss what is Supervised Learning Algorithms and the types of supervised learning algorithms in detail. You can also go through our other suggested articles to learn more–
