Updated March 15, 2023

Introduction to TensorFlow adam optimizer
The following article provides an outline for the TensorFlow adam optimizer. Adam stands for adaptive moment estimation, a method of calculating current gradients using prior gradients. The Adam optimization approach is a stochastic gradient descent extension that has lately gained traction in computer vision and natural language processing applications. The Adam optimizer is one of those unique algorithms that has proven to be effective across a wide range of learning methodologies. The primary idea behind this approach is to combine momentum and RMSprop.
Getting started TensorFlow Adam optimizer
TensorFlow provides a few optimization types and the necessity for others to define their class. There are two important steps in the optimizers:
1.apply gradients() updates the variables while computing
2.gradients() updates the gradients in the computational graph.
Adam uses an exponential declining average of the gradient and its squared to modify the parameters. The Adam technique is computationally efficient, requires little memory, is insensitive to diagonal rescaling of gradients, and is ideally suited for advanced analytics issues.”To implement Adam, set V _dw=0, S_ dw=0, and V_ dB, S_ dB =0. Then, while iterating ‘t,’ compute the derivatives dw,db using the current mini-batch, i.e., with mini-batch gradient descent. The momentum exponentially weighted average comes next.
V_ dw is equal to B.
We could use a way of reaching the optimization algorithm on each gradient descent step. We accomplish this by giving the minimum call to a handle.
x = adam.minimize(mse, var_list=x)
Adam Optimizer is the most popular and extensively used for neural network training.
The tf. train.adam() function in Tensorflow.js builds a tf. AdamOptimizer employs the adam optimizer algorithm.
tf. train. adam (learningRate? beta1? beta2?, epsilon?)
Adam class is defined as
tf.keras.optimizers.Adam(
learning_rate=0.001,
beta_1=0.9,
beta_2=0.999,
epsilon=1e-07,
amsgrad=False,
name="Adam",
**kwargs
)
The arguments are:
learning rate: A Tensor with no arguments returns the real number to utilize.
Beta: A float value or a constant float tensor is beta 1. The 1st-moment estimations’ exponential degradation rate. The default value is 0.9.
beta 2: A float value. The default value is 0.999.
epsilon is a tiny number that ensures numerical stability. 1e-7 is the default value.
amsgrad: This function returns a Boolean value. False is the default value.
name: A name for the operations that are created while applying gradients is optional. “Adam” is the default value.
Keyword arguments are referred to as kwargs.
opt = tf. keras. optimizers. Adam(learning_rate=0.2)
val1 = tf. Variable (10.0)
loss = lambda: (val1 ** 2)/2.0 # d(loss)/d(val1) == val1
step_count = opt. minimize (loss, [val1]).numpy()
val1.numpy()
And the Output is 9.8
TensorFlow provides a unique data type to facilitate the recording of gradient information to distinguish between tensors (such as parameters) that require calculating gradient information and conventional tensors that need not. Tf. variable. A variable may fit. Variable() Method transforms ordinary tensors into optimized tensors.
There are three ways to initialize the variable:
tf.global variables initializer should be used to initialize all global variables()
Use tf.variables initializer(list of vars) to set up variables we care about. This function can replace the global variable initializer: var name should only be used to initialize one variable.
initializer
It is good to deal with the first option. It’s important to remember that we should execute it inside a session. As a result, we will see the final session something like this:
as tf.Session() as sess:
sess.run(tf.global_variables_initializer())
Call initialize after adding optimizer.
Create your model
# Replace train op = tf. train with the optimizer train op = tf.train.
AdamOptimizer(1e-4).
minimize (cross entropy)
# Initialize variables with the operators.
tf. initialize all variables = init op ()
open the graph in a new window
tf.Session = sess ()
now initialize the variables
sess.run(init_op)
The training model is given as
sess.run(train op)
Adam uses an initial learning rate during computing. The reason most users don’t utilize learning rate decay with Adam is that the algorithm performs it for them:
t <- t + 1
lr_t <- learning_rate * sqrt (1 - beta2^t) / (1 - beta1^t)
where t0 is the initial time step, and lr_t is the new learning rate used.
Using Tensor Flow Adam Optimizer
The adam optimizer employs the adam algorithm, which uses the stochastic gradient descent method to carry out the optimization process. It’s simple to use and takes up very little memory. Therefore, it’s appropriate when there’s a lot of data and settings to work with.
Compared to the simple tf.train.GradientDescentOptimizer, Adam has various advantages. . Because it employs parameter moving averages, Adam can use a bigger effective step size, and the algorithm will converge to this step size without fine adjustment. However, the algorithm’s biggest disadvantage is that Adam necessitates additional computation for each parameter in each training cycle. A straightforward tf.train. GradientDescentOptimizer might also be used in the MLP, but it would need additional hyperparameter adjustment to converge quickly.
TensorFlow adam optimizer Examples
Given below is the example of a tensorflow adam optimizer:
Code:
const a = tf. tensor1d ([0, 1, 2, 3]);
const b = tf.tensor1d([1., 2., 5., 11.]);
const p = tf.scalar(Math.random()).variable();
const q = tf.scalar(Math.random()).variable();
const r = tf.scalar(Math.random()).variable();
// b = p * a^3 - q * a + r.
const d = a => p.mul(a.pow(3)).sub(q.mul(a)).add(r);
const ls = (pred, label) => pred.sub(label).square().mean();
const lrate = 0.01;
const opzr = tf.train.adam(lrate);
for (let j = 0; j < 10; j++) {
opzr.minimize(() => ls(f(a), b));
console.log(
`p: ${p.dataSync()}, q: ${q.dataSync()}, r: ${r.dataSync()}`);
}
const preds = f(a).dataSync();
preds.forEach((pred, j) => {
console.log (`a: ${j}, pred: ${pred}`);
});
Explanation
A simple quadratic function is created with a, b as input with tensors and p, q, and r as coefficients. The mean squared loss of the forecast is then calculated and passed to the Adam optimizer to minimize the loss and adjust the coefficient ideally. And the Output is shown as
Output:
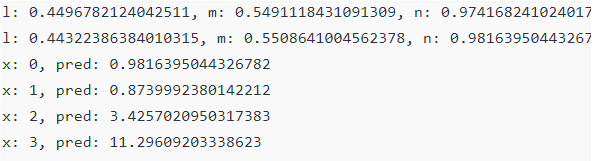
Conclusion
Choosing the correct optimizer and parameters for the neural network model can help us extract relevant accuracy of the result. Anyone new to deep learning will almost certainly receive the best and most consistent results using Adam, as it has previously been proven to perform well. However, in addition to storing learning rates, it also independently maintains momentum changes for each parameter.
Recommended Articles
This is a guide to tensorflow adam optimizer. Here we discuss the Using Tensor Flow Adam Optimizer along with the examples and outputs. You may also have a look at the following articles to learn more –
