Updated March 15, 2023
Introduction to TensorFlow Distributed
A TensorFlow API allows users to split training across several GPUs, computers, or TPUs. Using this API, we can distribute existing models and learning code with a few source codes. It takes a long time to train a machine learning model. As dataset sizes grow larger, it becomes increasingly difficult to train models in a short period. Distributed computing is used to overcome this.
What is TensorFlow Distributed?
TensorFlow provides distributed computing, allowing multiple processes to calculate different parts of the graph, even on different servers. This can also allocate computation to servers with strong GPUs while other computations are performed on servers with more memory. Furthermore, TensorFlow’s distributed training is based on data parallelism, which allows us to run different slices of input data on numerous devices while replicating the same model architecture.
How to use TensorFlow distributed?
Tf. distribute is TensorFlow’s principal distributed training method. Strategy. This approach allows users to send model training across several PCs, GPUs, or TPUs. It’s made simple to use, with good out-of-the-box performance and the ability to switch between strategies quickly. First, the total amount of data is divided into equal slices. Next, these slices are chosen depending on the training devices; after each slice, a model can be used to train on that slice. Because the data for each model is distinct, the parameters for each model are likewise distinct, so those weights must eventually be aggregated into the new master model.
TensorFlow can also read data in the TFRecord format with great efficiency. A TFRecord file is a set of binary records representing a single serialized instance of our input data.
The overall pipeline now reads:
1. Generate asset data records in the package
2. Using Dask, pre-process and serialize asset data in a distributed manner for each batch (or other scalers)
3. Create a TFRecord file for each session with serialized binary sets.
tf.distribute. the Strategy was created with the following important objectives in mind:
It’s simple to use and caters to many users, including researchers, machine learning engineers, and others.
Deliver excellent results right out of the box.
Switching between strategies is simple.
Mirrored Strategy
tf. distribute is a mirrored strategy. Mirrored Strategy is a technique for performing synchronous distributed training on many GPUs. Using this Strategy, we can construct clones of our model variables mirrored across the GPUs. These variables are collected together as a Mirrored Variable during operation and kept in sync with all-reduce techniques. NVIDIA NCCL provides the default algorithm; however, we can choose another pre-built alternative or develop a custom algorithm.
Creating mirrored type
mirrored_strategy = tf.distribute.MirroredStrategy()
TPU’s Strategy
One can use tf.spread.experimental.TPUStrategy to distribute training among TPUs. It contains a customized version of all-reduce that is optimized for TPUs.
Multiworker Mirrored Strategy
It’s a very specific strategy – multimachine multi-GPU.To manage the process, it replicates variables per device across the workers. So reduction is dependent on hardware and tensor sizes.
Architecture
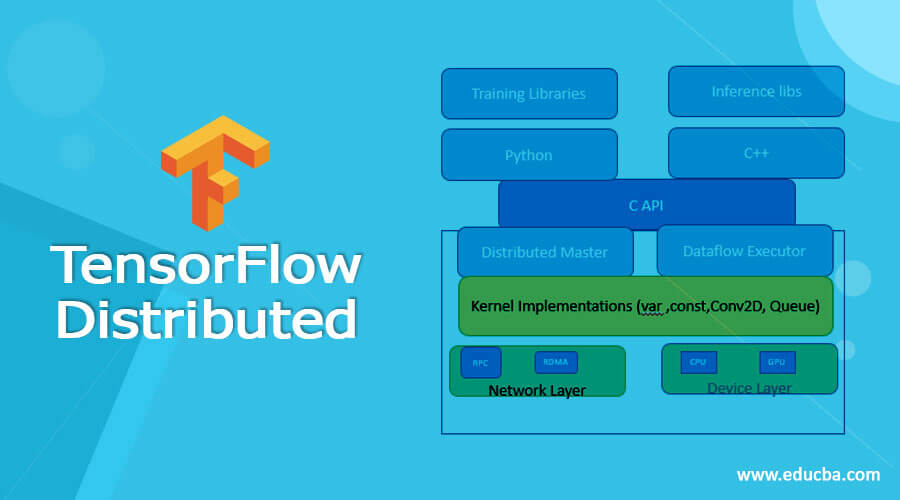
Going distributed allows us to train all of the huge models at the same time, which speeds up the training process. The architecture of the concept is seen below. A-C API separates the user-level code in multiple languages from the core runtime.
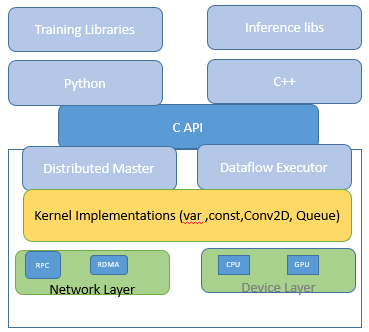
Client:
The users write the client TensorFlow application that creates the computation graph. Finally, the client establishes a session and sends the graph specification to the distributed master.
Distributed Master:
The distributed master prunes the graph to get the subgraph needed to evaluate the nodes the client has requested. The optimized subgraphs are then executed across a series of jobs in a coordinated manner.
Worker Service:
Each task’s worker service processes requests from the master. Kernels are sent to local devices by the worker service, which runs them in parallel. While training, workers compute gradients, typically stored on a GPU. If a worker or parameter server breaks, the chief worker controls failures and ensures fault tolerance. If the chief worker passes away, the training must be redone from the most recent checkpoint.
Kernel implementation
Several action kernels are performed with Eigen: Tensor, which generates effective feature code for multicore CPUs and GPUs using C++ templates.
Practical details to discuss
Creating two clusters before the servers are connected to execute each server in a separate process.
from multiprocessing import Process
from time import sleep
def s1():
ser1 = tf.train.Server(cluster,
j_name="local",
task_index=0)
se1 = tf.Session(ser1.target)
print("First server: running no-op...")
se1.run(tf.no_op())
print("First server: no-op run!")
ser1.join()
def s2():
for j in range(3):
print("Second server: %d seconds disconnected before connect..."
% (3 - j))
sleep(2.0)
ser2 = tf.train.Server(cluster,
j_name="local",
task_index=1)
print(" Second server : connected!")
ser2.join()
pr1 = Process(target=s1, daemon=True)
pr2 = Process(target=s2, daemon=True)
pr1.start()
pr2.start()
Example of TensorFlow Distributed
To execute distributed training, the training script must be adjusted and copied to all nodes.
work = ["localhost:2222", "localhost:2223"]
Next, each task is assigned a job with a collection of tasks. Therefore, the job com task is assigned as ‘local.’
jobs = {"local": tasks}
Starting a server
ser1 = tf.train.Server(cluster, j_name="local", task_index=0)
ser2 = tf.train.Server(cluster, j_name="local", task_index=1)
Next Executing on the same graph
tf.reset_default_graph()
v1 = tf.Variable(initial_value=0.0, name='variable')
see1 = tf.Session(ser1.target)
see2 = tf.Session(ser2.target)
The next modification done in the first server is reflected in another server.
se1.run(tf. global_variables_initializer())
se2.run(tf.global_variables_initializer())
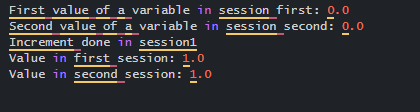
print("First value of a variable in session first:", se1.run(var))
print("Second value of a variable in session second:", se2.run(var))
se1.run(var.assign_add(1.0))
print("Increment done in session1")
print("Value in first session:", se1.run(var))
print("Value in second session:", se2.run(var))
Explanation
The above steps implement a cluster where the two servers act on it. And the output is shown as:
Result
Conclusion
We now understand what distributed TensorFlow can do and how to adapt your TensorFlow algorithms to execute distributed learning or parallel experiments. By employing a distributed training technique, users may greatly reduce training time and expense. Furthermore, the distributed training approach allowed developers to create large-scale and deep models.
Recommended Articles
This is a guide to TensorFlow Distributed. Here we discuss the Introduction, What is TensorFlow Distributed, and examples with code implementation. You may also have a look at the following articles to learn more –
