Updated April 20, 2023

Introduction to TensorFlow Random Forest
The following article provides an outline for TensorFlow Random Forest. This is one of the most often used Decision Forest training algorithms, employing several decision trees. A Random Forest is a cluster of deep CART decision trees trained without pruning and separately. Also, every tree is trained on a portion of the original training dataset chosen randomly (sampled with replacement).
What is TensorFlow random forest?
The Random Forest mixes hundreds or thousands of decision trees, each of which is trained on a slightly different set of compliances and splits bumps in each tree grounded on a small collection of attributes. The Random Forest final prognostications are calculated by comprising the prognostications of each tree. TensorFlow is a low-level library; we can consider it a collection of NumPy and SciPy that can be used to build machine learning algorithms. However, if we wish to construct deep learning algorithms, TensorFlow shines because it enables us to reap the benefits of GPUs for even more efficient implementation.
How to use random forest?
Random forests and gradient boosted trees are part of the TF-DF suite of production-ready algorithms for training, serving, and analyzing decision forest models. In addition, TensorFlow and Keras may now be used for classification, regression, and ranking problems thanks to their flexibility and configurability.
The model class specifies the learning algorithm. tfdf.keras.RandomForestModel(), for example. RandomForestModel() is a function that creates a Random Forest.
tfdf.keras.RandomForestModel(
*args, **kargs
)The Forest model is as follows:
- First, choose random samples from a set of data.
- Then, for each sample, create a decision tree and acquire a forecast result from each decision tree.
- Then, cast a vote for each expected outcome.
As the final forecast, choose the prediction with the most votes.
The example for the algorithm is shown as
import tensorflow_decision_forests as tfds
import pandas as pd
dataset = pd.read_csv("demo/dataset.csv")
tf_dataset = tfds.keras.pd_dataframe_to_tf_dataset(dataset, label="my_label")
model = tfds.keras.RandomForestModel()
model.fit(tf_dataset)
print(model.summary())This library can bridge the extensive TensorFlow ecosystem by making it simple to connect tree-based models with numerous TensorFlow tools, libraries, and platforms like TFX.
TensorFlow random forest model
It is based on the concept of bagging, which involves merging the results of many Decision trees on distinct samples of the data set to reduce variation in predictions. The random forest method offers more randomness and diversity by using the bagging approach to the feature space. It randomly samples elements rather than looking greedily for the best predictors to generate branches.
Random Forest can handle both classification and regression problems.
It can handle huge datasets with a lot of dimensionalities.
It improves the model’s accuracy and eliminates the problem of overfitting.
TensorFlow Decision Forests Installation
pip install tensorflow_decision_forestsImport the libraries
import os
import numpy as np
import pandas as pd
import TensorFlow as tf
import mathNext is to train a Random Forest model. Let’s see the steps and the dataset used. We train, assess, analyze, and export a binary classification, Random Forest, on the Palmer’s Penguins dataset. There are eight variables in this dataset (n = 344 penguins). There are numerical (e.g., bill depth mm), categorical (e.g., island), and missing characteristics in the dataset. These feature classes are supported natively by TF-DF, and no pre-processing is required.
Step 1
Loading a dataset
import tensorflow_decision_forests as tfdf
dataset_df = pd.read_csv("https://cdn.educba.com/demo/penguins.csv")To display, use the head function
dataset_df.head(3)The labels are assigned as a string
label = "species"
classes = dataset_df[label]. unique().tolist()
print (f"Label classes are hiven as: {classes}")
dataset_df[label] = dataset_df[label].map(classes.index)Step-2: Splitting a dataset- splitting a dataframe into two
def split_dataset(dataset, test_ratio=0.30):
test_indices = np.random.rand(len(dataset)) < test_ratio
return dataset[~test_indices], dataset[test_indices]
train_ds_pd, test_ds_pd = split_dataset(dataset_df)
print("{} Training examples are, {} Testing examples are.”. format(
len(train_ds_pd), len(test_ds_pd)))
Training a model
%set_cell_height 300
mdl_1 = tfdf. keras.RandomForestModel ()
mdl_1. compile (
metrics=["accuracy"])
with sys_pipes():
mdl_1.fit(x=train_ds)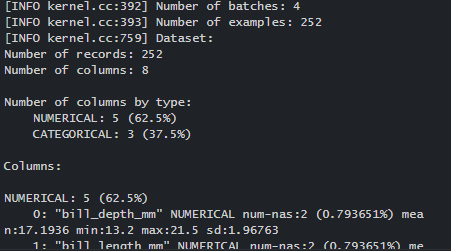
Training a model is given as
model = tfdf.keras.RandomForestModel()
model.fit(train_ds)Random forest for classification is given as
rf_mdl = RandomForestClassifier(n_estimators=200)
rf_mdl.fit(A_train_scaled, b_train)
RandomForestClassifier (bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=200, n_jobs=None,
oob_score=False, random_state=None, verbose=0,
warm_start=False)// Predictions
rf_pred = rf_mdl.predict(A_test_scaled)
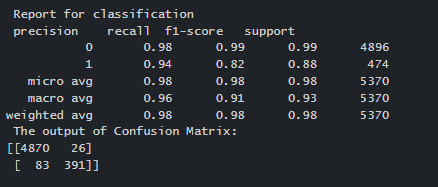
print('Report for classification: \n')
print(classification_report(b_test,rf_pred))
print ('\nThe Output of Confusion Matrix is: \n')
print(confusion_matrix(b_test,rf_pred))Output
TensorFlow random forest examples
TensorFlow Decision Forests (TF-DF) is a library that allows users to train, evaluate, interpret, and infer Decision Forest models using TensorFlow.
When comparing the results of TensorFlow and Random Forest models, it becomes clear that the precision of the results is quite high and may be used to forecast future values.
Example #1
Code:
import tensorflow_decision_forests as tfdf
import pandas as pd
train_df = pd.read_csv("demo/d_train.csv")
test_df = pd.read_csv("demo/d_test.csv")
train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(train_df, label="my_label")
test_ds = tfdf.keras.pd_dataframe_to_tf_dataset(test_df, label="my_label")
model = tfdf.keras.RandomForestModel()
model.fit(train_ds)
model.summary()
model.evaluate(test_ds)
model.save("demo/model")Example #2
Using Random Forest in Tensor Flow
Code:
import tensorflow as tf
from tensorflow.python.ops import resources
from tensorflow.contrib.tensor_forest.python import tensor_forest
import os
os.environ["CUDA_VISIBLE_DEVICES"] = ""
from tensorflow.demo.blogs.mnist import input_data
mnist = input_data.read_data_sets("/drive/fold/", one_hot=False)
n_steps = 500
ba_size = 1024
n_classes = 10
n_features = 784
n_trees = 10
max_nodes = 1000
A = tf.placeholder(tf.float32, shape=[None, n_features])
B = tf.placeholder(tf.int32, shape=[None])
hparams = tensor_forest.ForestHParams(n_classes=n_classes,
n_features=n_features,
n_trees=n_trees,
max_nodes=max_nodes).fill()
forest_graph = tensor_forest.RandomForestGraphs(hparams)
train_op = forest_graph.training_graph(A, B)
loss_op = forest_graph.training_loss(A, B)
infer_op, _, _ = forest_graph.inference_graph(A)
correct_prediction = tf.equal(tf.argmax(infer_op, 1), tf.cast(Y, tf.int64))
accuracy_op = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
init_vars = tf.group(tf.global_variables_initializer(),
resources.initialize_resources(resources.shared_resources()))
sess = tf.train.MonitoredSession()
sess.run(init_vars)
for j in range(1, num_steps + 1):
batch_a, batch_b = mnist.train.next_batch(batch_size)
_, l = sess.run([train_op, loss_op], feed_dict={A: batch_a, B: batch_b})
if j % 50 == 0 or j == 1:
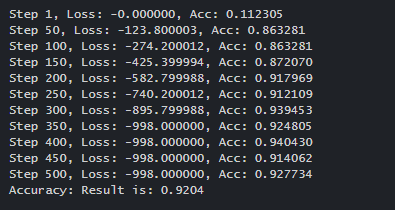
acc = sess.run(accuracy_op, feed_dict={A: batch_a, B: batch_b})
print('Step %j, Loss: %f, Acc: %f' % (j, l, acc))
test_a, test_a = mnist.test.images, mnist.test.labels
print("Accuracy result is:", sess.run(accuracy_op, feed_dict={A: test_a, B: test_b}))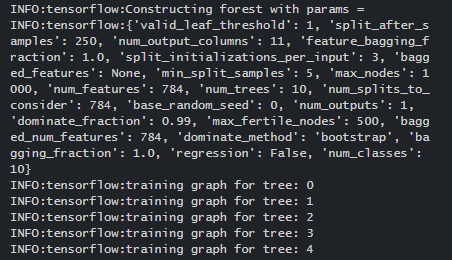
Conclusion
We learned what random forests are, how they function, and how to find essential features in this post. We also learned how to design models, evaluate them, and locate key aspects in Tensor Flow, a good feature selection indicator. Users unfamiliar with neural networks can use decision forests to get started with TensorFlow and then go to more powerful neural networks.
Recommended Articles
We hope that this EDUCBA information on “TensorFlow Random Forest” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
