Introduction to Ternary Search Algorithm
The Ternary Search Algorithm is a divide-and-conquer search algorithm utilized to determine the position of a target value within a sorted array. It operates on the principle of repeatedly dividing the search interval into three parts and narrowing down the possible locations of the target. This algorithm is handy for searching within ordered data structures where traditional binary search may not be efficient. Introduced as an extension of binary search, it offers more optimization by dividing the search space into three segments instead of two. Ternary search can be applied to various scenarios, including finding an unimodal function’s maximum or minimum value, locating a specific point within a continuous range, or searching within a sorted array. Its effectiveness significantly reduces the search space with each iteration, resulting in a faster search process.
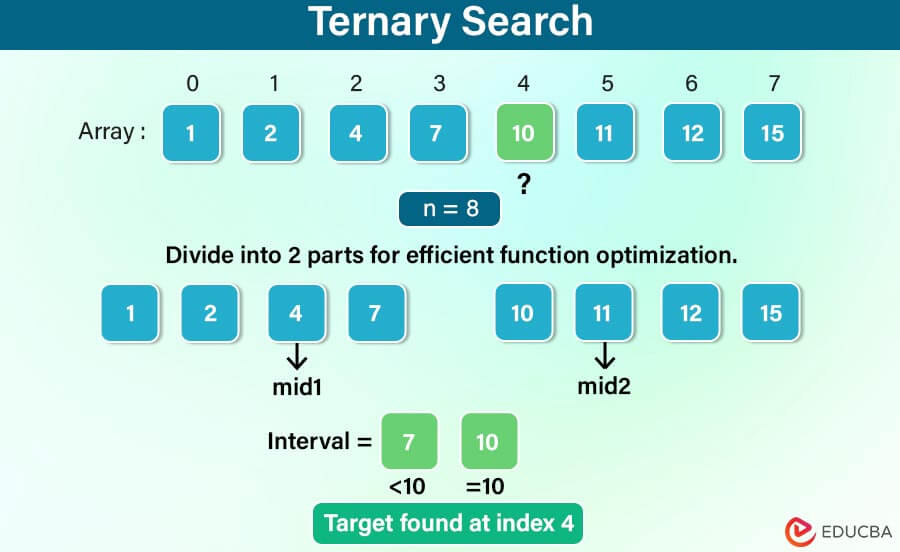
Table of Contents
Understanding Ternary Search
Understanding Ternary Search involves delving into its core concept and principles. Ternary Search bases itself on repeatedly dividing the search interval into three parts instead of two, as in binary search. This approach enables more efficient narrowing of the search space, especially in scenarios where the search domain is relatively large and needs finer granularity.
Concept
It shine for a specific type of function: unimodal functions, which resemble a roller coaster ride. It surpasses binary search in such scenarios. While binary search halves the search area each time, ternary search cleverly divides it into thirds and evaluates two key points. Comparing these elevations eliminates a large chunk of the irrelevant area, converging on the target value much faster. However, this efficiency comes with a caveat: ternary search is only effective for unimodal functions.
Principles
Principles guiding the effectiveness of Ternary Search encompass its adaptability to sorted arrays, the logarithmic time complexity it exhibits, and its adept handling of uniformly spread data distributions. Understanding these foundational principles is pivotal for harnessing the full potential of Ternary Search across a spectrum of applications, ranging from navigating through ordered datasets to fine-tuning algorithms for tasks demanding optimal performance.
How Ternary Search Works
Algorithm Explanation
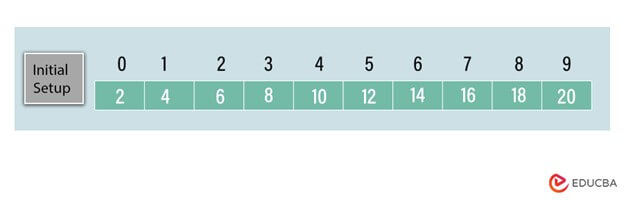
Consider we have a sorted array [2, 4, 6, 8, 10, 12, 14, 16, 18, 20] and we want to search for the target value 12.
- Initial Setup:
We start with the entire sorted array
- Calculate Midpoints:
We calculate two midpoints:
Here,
left = 0, right = 9, so:
- Comparison:
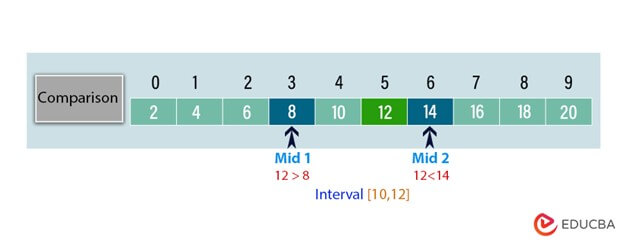
We compare the target value 12 with the elements at midpoints 3 and 6:
array[3] = 8 (less than 12) (i.e., key>ar[mid1])
array[6] = 14 (greater than 12) (i.e., key<ar[mid2])
- Narrow down the search space:
Since 12 is greater than 8 and less than 14, we discard one-third of the data and narrow the search interval to [10, 12].
- Recursive Process:
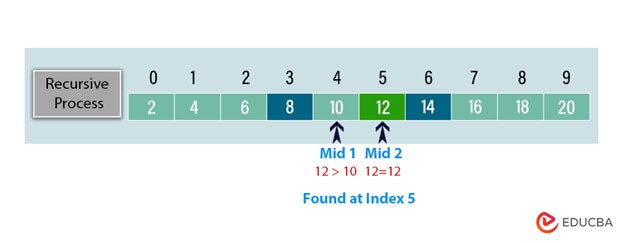
We recursively repeat the above steps on the narrowed search interval [10, 12].
So, left = 3, right = 6
Step 2: Calculate midpoints:
mid1 = 3 + (6 – 3) / 3 = 3 + 1 = 4
mid2 = 6 – (6 – 3) / 3 = 6 – 1 = 5
Step 3: Comparison:
array[5] = 12 (matches the target value)
Pseudocode
Code:
ternary_search(array, target):
left = 0
right = length(array) - 1
while left <= right:
mid1 = left + (right - left) / 3
mid2 = right - (right - left) / 3
if array[mid1] == target:
return mid1
if array[mid2] == target:
return mid2
if target < array[mid1]: right = mid1 - 1 elif target > array[mid2]:
left = mid2 + 1
else:
left = mid1 + 1
right = mid2 - 1
return NOT_FOUNDExplanation:
- We start by initializing two pointers, left and right, which define the boundaries of the search interval.
- Inside the while loop, we compute midpoints mid1 and mid2 to partition the search interval into three segments.
- We examine if the target value matches either mid1 or mid2. If we find a match, we return their corresponding indices.
- Depending on the target value compared with mid1 and mid2, we adjust the search interval boundaries by updating left and right.
- If the algorithm doesn’t find the target value within the current search interval, we return a NOT_FOUND
Time Complexity
The Ternary Search algorithm exhibits the following time complexities:
Best Case: O(1)
- The best-case scenario happens when the algorithm finds the target element at the first midpoint.
- In this case, the algorithm terminates after a single comparison, resulting in constant time complexity.
Worst Case: O(log3(N))
- The target element may not exist in the search space or may be found at the previous iteration, in the worst case scenario.
- The search space is reduced by a factor of 1/3 in each iteration, leading to logarithmic time complexity.
- Despite a logarithmic factor, Ternary Search typically outperforms binary search for large datasets because it divides the search space into three segments, resulting in fewer comparisons.
Space Complexity
The space complexity of the Ternary Search algorithm is O(1), indicating that it requires a fixed amount of additional memory irrespective of the input size.
- It typically relies on a few variables to maintain indices and calculate midpoints, which do not increase with the input size.
- The algorithm does not require additional memory allocation for data structures such as stacks or queues, contributing to efficient memory use.
Examples
Example 1
Code:
def ternary_search(arr, target):
left, right = 0, len(arr) - 1
while left <= right:
mid1 = left + (right - left) // 3
mid2 = right - (right - left) // 3
if arr[mid1] == target:
return mid1
if arr[mid2] == target:
return mid2
if target < arr[mid1]: right = mid1 - 1 elif target > arr[mid2]:
left = mid2 + 1
else:
left = mid1 + 1
right = mid2 - 1
return -1
# Example Usage:
arr = [2, 4, 6, 8, 10, 12, 14, 16, 18, 20]
target = 12
print("Index of", target, ":", ternary_search(arr, target))Output:
![]()
Time Complexity:
O(log3(N))
Example 2
Code:
def ternary_search_best_case(arr, target):
if arr[0] == target:
return 0
if arr[-1] == target:
return len(arr) - 1
left, right = 0, len(arr) - 1
while left <= right:
mid1 = left + (right - left) // 3
mid2 = right - (right - left) // 3
if arr[mid1] == target:
return mid1
if arr[mid2] == target:
return mid2
if target < arr[mid1]: right = mid1 - 1 elif target > arr[mid2]:
left = mid2 + 1
else:
left = mid1 + 1
right = mid2 - 1
return -1
# Example Usage:
arr = [1, 3, 5, 7, 9, 11, 13, 15, 17, 19]
target = 1
print("Index of", target, ":", ternary_search_best_case(arr, target))Output:
![]()
Time Complexity:
O(1)
Pros and Cons
Pros
- Efficient Search: It is highly efficient for searching within sorted arrays, providing a time complexity of O(log3(N)), with N representing the size of the array. It outperforms linear search and can be more versatile than binary search for specific datasets.
- Divide-and-Conquer Approach: Ternary Search follows a divide-and-conquer approach, dividing the search space into three segments at each step. This approach enables faster narrowing down of the search interval than binary search, especially for larger datasets.
- Versatility: It can be applied to various scenarios, including finding the maximum or minimum value of an unimodal function, locating a specific point within a continuous range, or searching within a sorted array. Its adaptability makes it a valuable tool in algorithm design.
Cons
- Limited Applicability: It applies only to scenarios where efficiently dividing the search space into three segments is possible. Alternative search algorithms may be more suitable in cases where this is not feasible, such as non-sorted or irregularly distributed data.
- Space Complexity: Although Ternary Search has a low space complexity of O(1), which requires constant additional memory, its recursive nature may lead to stack overflow errors for vast search spaces. Consider this limitation when implementing the algorithm.
- Not Always Optimal: While Ternary Search offers an efficient search process in many cases, it may not always provide the optimal solution. Depending on the dataset’s characteristics and the specific search requirements, other algorithms, such as binary search or interpolation search, may be more appropriate.
Applications and Use Cases
Finding Local Extremes
It is often used to find an unimodal function’s local maximum or minimum, where the function increases and then decreases (or vice versa) within a specific range. Ternary Search efficiently locates the function’s peak or valley by iteratively narrowing down the search space.
Range Queries
When data follows a uniform distribution or displays specific patterns, Ternary Search proves adept at pinpointing particular points within a continuous span. This capability lends itself well to conducting range queries in data structures such as arrays or trees, where the task involves identifying elements within a defined range.
Searching in Ordered Collection
It excels in searching within ordered collections, such as sorted arrays or linked lists. It offers a faster alternative to linear search by significantly reducing the search space with each iteration, improving search efficiency for large datasets.
Numerical Analysis
Numerical analysis utilizes Ternary Search for tasks such as root finding or solving equations. By iteratively narrowing down the search interval, it efficiently converges toward the root or solution of the equation, providing accurate results with fewer iterations compared to other methods.
Game Development
It demonstrates proficiency in locating specific points within continuous ranges, especially when dealing with uniformly distributed or patterned data. This feature makes it particularly valuable for conducting range queries within data structures like arrays or trees, where the objective is to identify elements falling within specified intervals.
Algorithm Design
It plays a fundamental role in algorithm design, showcasing the efficacy of divide-and-conquer methodologies. Its underlying principles and strategies catalyze crafting more intricate algorithms to tackle many computational challenges.
Conclusion
Ternary Search emerges as a robust algorithm within the domains of search and optimization. Its proficiency in swiftly identifying target values within sorted arrays and its adaptable nature for diverse applications, including discovering local extremes, conducting range queries, and optimizing parameters, solidify its importance in algorithmic design and problem-solving. Employing a divide-and-conquer strategy and boasting logarithmic time complexity, Ternary Search offers a compelling alternative in scenarios where traditional methods like linear or binary search prove insufficient. With a grasp of its principles, benefits, and constraints, developers can effectively harness Ternary Search to tackle a broad spectrum of computational challenges.
Frequently Asked Questions (FAQs)
Q1. Can Ternary Search be used for non-numeric data?
Answer: Ternary Search applies to non-numeric data, provided it’s sorted and comparable. It can search through strings and characters or compare other data types.
Q2. Can Ternary Search handle duplicate values in the array?
Answer: Ternary Search effectively manages duplicate values within the array, ensuring that it identifies all occurrences of the target value within the search interval.
Q3. Can Ternary Search be applied to multidimensional arrays?
Answer: Though originally crafted for one-dimensional arrays, Ternary Search extends to multidimensional arrays by recursively applying the algorithm across each dimension.
Recommended Articles
We hope that this EDUCBA information on “Ternary Search” was beneficial to you. You can view EDUCBA’s recommended articles for more information,
