Introduction- Train and Test in ML
Machine learning, a cornerstone of artificial intelligence, ML empowers computers to improve performance by learning from data without the need for explicit programming. At its essence, the training and testing process forms the backbone of every machine learning model. Data splitting is pivotal to evaluating the model’s performance on unseen data for real-world applicability. Without proper division, biased results and inaccurate assessments may ensue, underscoring the importance of thoughtful data partitioning.
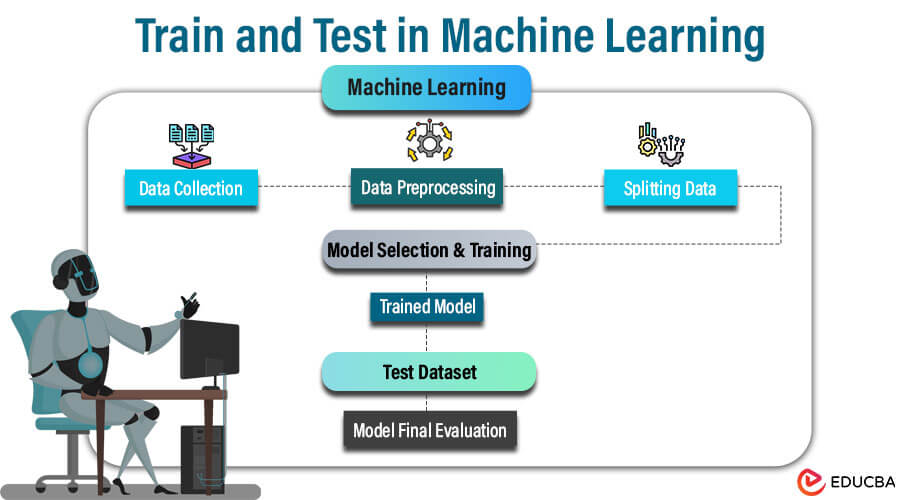
Table of Contents
The Role of Training Data
The training data is crucial in machine learning, serving as the cornerstone of model development and refinement.
Definition
Training data constitutes a selected portion of labeled instances to instruct machine learning models to identify patterns, characteristics, and correlations within the dataset. These instances usually comprise pairs of input and output, where the input denotes the features or attributes, and the output corresponds to the target variable or class label. They can render precise predictions or classifications on unseen data by acquiring models with varied and inclusive samples during training.
Importance
- Role in Performance and Generalization
Training data significantly influences model performance and generalization capabilities by providing the foundation for learning patterns and relationships within the data.
- Extracting Relevant Insights
Exposure to diverse examples allows models to extract relevant insights, enhancing their ability to make informed decisions in real-world scenarios.
- Ensuring Robustness
Quality training data ensures that models can generalize well beyond the examples they have seen, enhancing their robustness and reliability across different environments.
- Facilitating Informed Decision-Making
Learning from a varied dataset enables models to make accurate predictions or classifications on unseen data, enabling them to perform effectively in diverse contexts.
Techniques
Researchers utilize various techniques to enhance the role of training data in machine learning, improve model performance, and address potential hurdles.
- Data augmentation methods, including rotation, flipping, or cropping, generate extra training instances, enriching dataset diversity and complexity.
- Techniques like oversampling and undersampling are employed to tackle class imbalances within the data, ensuring equitable representation and mitigating biases.
- Ensemble methods amalgamate multiple models trained on diverse subsets of the training data to enhance predictive accuracy and overall model robustness.
Understanding the Test Data
Understanding the role of test data is essential in evaluating machine learning models’ performance and generalization capability.
Definition
Test data, comprising a subset of labeled instances separate from the training dataset, is used exclusively to evaluate machine learning models’ performance. These instances represent unseen examples the model hasn’t encountered during its training phase. Using test data aids in determining the model’s ability to generalize to fresh, unseen examples, thereby offering valuable insights into its practical efficacy.
Importance
- Unbiased Evaluation: Test data is crucial for objectively assessing model performance. Evaluation of unseen data offers a reliable measure of the model’s ability to generalize beyond the training set.
- Identification of Issues: Test data assists in identifying potential problems like overfitting or underfitting. By observing how the model performs on unseen examples, practitioners can discern whether it has learned genuine patterns or has merely memorized the training data.
- Fine-Tuning Models: The insights gained from testing enable practitioners to refine their models for enhanced performance. By pinpointing weaknesses revealed during testing, The team can make adjustments to improve the model’s effectiveness in real-world applications.
- Enhanced Accuracy: Utilizing test data ensures that we base the model’s performance metrics on its ability to generalize to new situations and unseen instances. This instance ultimately leads to more accurate assessments of the model’s efficacy in practical scenarios.
Techniques
- Holdout Approach: This method entails reserving a portion of the dataset exclusively for testing while using the remaining data to train the model. The holdout method provides a dependable estimation of its performance by ensuring that assessors evaluate the model on unseen instances.
- Cross-Validation Technique: Cross-validation divides the dataset into multiple subsets, employing each subset alternately for training and testing. This iterative process achieves a more robust model performance evaluation by averaging results across different dataset partitions.
- Metrics Assessment: To evaluate model performance on test data, various metrics, such as accuracy, precision, recall, and F1 score, are employed. These metrics offer quantitative insights into the model’s efficacy in making predictions or classifications on unseen examples.
Why Split Data into Training and Testing?
Partitioning data into training and testing subsets is a fundamental procedure in machine learning, pivotal for various reasons such as mitigating overfitting, fostering generalization, and facilitating robust model evaluation. Let’s delve into these aspects, supplemented by an illustrative example featuring a dataset sheet:
1. Overfitting Mitigation
Practitioners can evaluate the performance of models on unseen data by partitioning the dataset into training and testing subsets. This evaluation helps identify instances where the model has overfit the training data, capturing noise or irrelevant patterns that do not generalize well to new cases.
Example:
Consider a dataset containing information about housing prices, with features such as square footage, number of bedrooms, and location.
| Square Footage | Number of Bedrooms | Location | Price (in $) |
| 1500 | 3 | Suburb | 250000 |
| 2000 | 4 | Urban | 380000 |
| 1200 | 2 | Rural | 180000 |
| 1800 | 3 | Suburb | 300000 |
| 1600 | 3 | Urban | 270000 |
We may observe high accuracy if we train our model using all 5 data points and then test it on the same set. However, this doesn’t guarantee that our model will perform well on new, unseen data. By splitting the dataset into training (say, 4 data points) and testing (1 data point) sets, the team trains the model using the training set and then assesses it using the testing set. It helps us identify whether the model has overfit the training data by memorizing specific patterns that don’t generalize well to new data.
Training Set (80% of data):
| Square Footage | Number of Bedrooms | Location | Price (in $) |
| 1500 | 3 | Suburb | 250000 |
| 2000 | 4 | Urban | 380000 |
| 1200 | 2 | Rural | 180000 |
| 1800 | 3 | Suburb | 300000 |
Testing Set (20% of data):
| Square Footage | Number of Bedrooms | Location | Price (in $) |
| 1600 | 3 | Urban | 270000 |
2. Facilitating Generalization
Splitting data into training and testing subsets offers a method for impartially evaluating the model’s performance. By comparing model predictions with actual outcomes on the testing set, practitioners can assess the model’s accuracy and dependability, facilitating informed decisions regarding model selection and refinement.
Example:
Suppose the housing pricing dataset model can accurately predict prices for the testing set. This model indicates that it has successfully learned to generalize the underlying patterns from the training data to new, unseen instances, which is crucial for ensuring the model makes accurate predictions in real-world scenarios.
3. Effective Model Evaluation
Dividing data into training and testing subsets offers a way to assess the model’s performance without bias. By comparing model predictions with actual testing outcomes, practitioners can accurately measure the model’s precision and dependability, aiding in informed decisions regarding model selection and refinement.
Example:
After training and testing our model for the same house pricing dataset, we can evaluate its performance by comparing its predictions against the actual prices in the testing set. If the model’s predictions closely match the actual prices, the model is reliable and accurate. On the other hand, if there’s a significant disparity between the predicted and actual prices, it may indicate areas where the model needs improvement. This evaluation process guides us in making informed decisions about model selection and refinement, ensuring its effectiveness in practical applications.
Techniques for Robust Evaluation – Train and Test in Machine Learning
1. Cross Validation
Cross-validation entails dividing the dataset into several subsets called folds. The model is trained on a blend of folds and assessed on the remaining fold. This iterative process is carried out multiple times, with each fold utilized alternatively for training and testing purposes.
Cross-validation enhances the model’s performance estimate by using the complete dataset for both training and testing purposes. This approach evaluates the model’s generalization across diverse data samples, mitigating the risks associated with overfitting or underfitting.
Example:
In a 5-fold cross-validation setup, We divide the dataset into 5 equal parts. We train the models on 4 folds and evaluate on the remaining fold. This process is repeated 5 times, each time with a different fold held out for testing, and we average the performance metrics over all iterations to obtain a robust estimate of model performance.
2. Hyperparameter Tuning and Validation set
Hyperparameters are parameters the model does not directly learn during training but affect the learning process. Hyperparameter tuning involves selecting the optimal values for these parameters to improve model performance.
A distinct validation set is employed to avoid overfitting the test set during hyperparameter tuning. The model undergoes training on the training set. The team tests various hyperparameter configurations on the validation set to identify the most effective model.
Example:
In a grid search for hyperparameter tuning, the team tries various combinations of hyperparameters. We evaluate the performance of each configuration on the validation set. We then select the configuration that yields the best performance on the validation set for final evaluation on the test set.
3. Time-Series & Imbalanced Data Considerations
- Time-Series Data:
Researchers utilize methods like temporal cross-validation to handle time-series data, maintaining the chronological sequence of data in training and testing sets. It ensures that the model is assessed on data instances occurring after the training data, closely resembling real-world deployment conditions.
- Imbalanced Data:
In cases of imbalanced data, where one class is significantly more prevalent than others, techniques such as stratified sampling and resampling methods (e.g., oversampling minority class, undersampling majority class) are used to ensure balanced representation during training and evaluation.
Dangers of Data Leakage -Train and Test in Machine Learning
Data leakage refers to unintentionally incorporating information from the testing or validation set into the training process, which can lead to inflated performance metrics and unreliable model evaluations.
1. Consequences
- Inflated Performance Metrics: Data leakage has the potential to artificially elevate the performance metrics of a model during training, creating a deceptive impression of its efficacy. Consequently, this may lead to deploying models with poor generalization to new, unseen data.
- Misleading Model Evaluations: Models trained on leaked data might demonstrate strong performance during testing but could fail to provide accurate predictions in real-world scenarios. Such discrepancies can result in significant errors and raise doubts about the model’s reliability.
- Loss of Trust and Credibility: Data leakage threatens the trustworthiness of machine learning models, undermining their integrity and credibility. Stakeholders may question the validity of model predictions, leading to hesitancy in relying on them for decision-making purposes.
2. Causes
- Errors in Feature Engineering: Data leakage frequently arises from unintended errors in feature engineering, such as inadvertently incorporating information from the validation or testing sets into the training process.
- Leaking Features: Some features within the dataset may directly or indirectly divulge information about the target variable, thereby risking data leakage if not managed appropriately.
- Improper Cross-Validation Techniques: Data leakage can also result from inappropriate cross-validation methods, such as employing time series data without accounting for temporal dependencies. Such oversights can lead to unintended information leakage across different folds during model training.
3. Prevention
- Ensuring Proper Separation of Training and Testing Data: Maintaining a strict partition between training, validation, and testing datasets is critical to prevent data leakage. Data must not inadvertently transfer from the validation or testing sets into the training phase.
- Prudent Feature Engineering: Feature engineering demands careful execution to evade the inclusion of information from the validation or testing sets. Features ought to be constructed solely based on the available data at the time of prediction, minimizing the risk of data leakage.
- Employing Reliable Cross-Validation Techniques: Using dependable cross-validation methods, such as stratified sampling or time-series cross-validation, is crucial. These techniques play a pivotal role in mitigating data leakage and ensuring the credibility of model evaluations.
Case Studies- Train and Test in Machine Learning
Case Study 1: Classification Problem
In this scenario, we’ll delve into a classification challenge centered on predicting customer churn for a telecommunications company. The dataset comprises various features, including customer demographics, usage patterns, and subscription particulars. The target variable signifies whether a customer has churned (1) or remained active (0).
| Customer ID | Age | Gender | Subscription Type | Monthly Charges | Total Charges | Churn |
| 1 | 45 | Male | Premium | 80 | 2400 | 0 |
| 2 | 30 | Female | Basic | 50 | 600 | 1 |
| 3 | 55 | Female | Premium | 100 | 3500 | 0 |
| 4 | 35 | Male | Basic | 60 | 1800 | 0 |
| 5 | 50 | Male | Premium | 90 | 4500 | 1 |
Approach:
- Data Preparation: The dataset undergoes preprocessing stages like handling missing data, encoding categorical variables, and scaling numerical features.
- Feature Selection: Utilize correlation analysis and recursive feature elimination methods to pinpoint the most pertinent features for forecasting customer churn.
- Model Building: Train and assess the dataset using various classification algorithms, including logistic regression, random forests, decision trees, and SVM.
- Model Evaluation: Performance metrics like accuracy, precision, and recall, and we compute F1-scores to evaluate the efficacy of the models in predicting customer churn.
Case Study 2: Importance of Representative Test Set
| Transaction ID | Amount | Type | Fraudulent |
| 1 | 100 | Purchase | 0 |
| 2 | 180 | Purchase | 1 |
| 3 | 120 | Purchase | 0 |
| 4 | 200 | Purchase | 0 |
| 5 | 220 | Purchase | 1 |
Scenario:
- Imbalanced Dataset: The dataset comprises transaction data for a retail company, where fraudulent transactions are significantly less prevalent than legitimate ones.
- Model Training: The team trains a machine learning model on the imbalanced dataset without addressing class imbalance.
- Model Evaluation: The model’s performance on the test set appears high. However, further analysis reveals its inefficacy in detecting fraudulent transactions due to the test set’s imbalance.
- Consequences: Relying solely on accuracy as a performance metric may lead to erroneous conclusions regarding the model’s effectiveness. The model’s inability to identify fraudulent transactions could have severe financial repercussions for the retail company.
Key Takeaway For Case Studies:
This case study highlights the significance of employing a well-represented test set, especially when data is imbalanced or events are rare. Assessing models on biased test sets can yield inaccurate evaluations of model performance, potentially resulting in costly errors in practical scenarios.
Conclusion
Training and testing in machine learning is essential for developing reliable models capable of making accurate predictions or classifications on unseen data. Proper data splitting, including train-test splitting and cross-validation, ensures unbiased evaluation and robust model performance. Understanding the roles of training and test data, along with techniques for effective evaluation, such as hyperparameter tuning and addressing imbalanced data, is crucial. Moreover, preventing data leakage and employing representative test sets are vital for trustworthy model assessments, ultimately enhancing model effectiveness in real-world applications.
Frequently Asked Questions (FAQs)
Q1. How can time-series data be handled in machine learning?
Answer: Time-series data, characterized by observations recorded at successive intervals, necessitates unique treatment in machine learning. Methods such as temporal cross-validation are employed to preserve the chronological order of data in training and testing sets. This data ensures that models are assessed on data instances occurring after the training data, mirroring real-world deployment conditions. By adopting this approach, we accurately evaluate the model’s performance in time-dependent scenarios.
Q2. What are some consequences of relying solely on accuracy as a performance metric in machine learning?
Answer: Depending solely on accuracy as a performance measure can yield misleading assessments of a model’s efficacy, especially in imbalanced datasets. In such instances where one class dominates, we may attain high accuracy by predicting the majority class. This consequence could obscure the model’s incapacity to accurately recognize minority classes, like fraudulent transactions or uncommon events, posing potential financial or operational hazards. Hence, it’s crucial to factor in supplementary metrics such as precision, recall, and F1-score to grasp a model’s performance thoroughly.
Q3. How does regularization prevent overfitting in machine learning?
Answer: Regularization is a method to mitigate overfitting by incorporating a penalty term into the model’s loss function. This penalty discourages overly complex models by penalizing large coefficients or parameters, leading to smoother decision boundaries and improved generalization performance on unseen data.
Recommended Articles
We hope that this EDUCBA information on “Train and Test in Machine Learning” was beneficial to you. You can view EDUCBA’s recommended articles for more information,
