Updated November 16, 2023
Introduction to Transformer Model
The Transformer model represents a groundbreaking natural language processing and artificial intelligence advancement. It revolutionized how machines understand and generate human language by introducing a novel architecture based on self-attention mechanisms. Unlike earlier models, Transformers are highly effective for tasks like language translation, text generation, etc, due to their efficient capture of long-range dependencies in data. Their success has led to the development of various Transformer variants, each tailored for specific applications. This article delves into the core components and workings of Transformer models, shedding light on their pivotal role in modern machine learning.
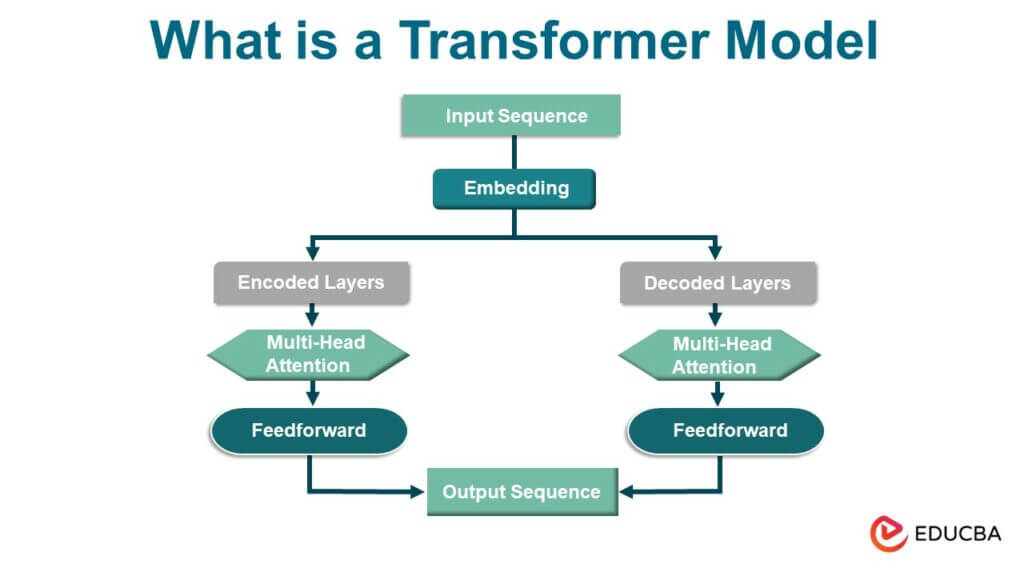
Table of Contents
- Introduction to Transformer Models
- What Can Transformer Models Do?
- Transformer Architecture
- Self-Attention Mechanism
- Multi-Head Attention
- Layer Normalization and Residual Connections
- Transformer Variants
- Pre-training and Fine-tuning
- Transformer model implementations
- Advantages of RNNs and CNNs
- Challenges and Limitations
- Future Directions
What Can Transformer Models Do?
Transformer model are versatile and can perform a wide range of tasks, including:
- Natural Language Processing (NLP): They excel in tasks like language translation, sentiment analysis, text summarization, and question-answering.
- Image Processing: Transformers can process images for tasks like image captioning, object detection, and even generating art.
- Speech Recognition: They’re used in speech-to-text systems and voice assistants.
- Recommendation Systems: Transformers are used to power recommendation engines, which help improve the accuracy of personalized content suggestions.
- Drug Discovery: Transformers assist in drug molecule generation and predicting drug interactions.
- Conversational AI: They enable chatbots and virtual assistants to have more natural and context-aware conversations.
- Anomaly Detection: Transformers can detect anomalies in data, which is vital for fraud detection and network security.
- Language Generation: They are adept at generating human-like text, making them valuable for chatbots, content creation, and creative writing.
Transformer Architecture
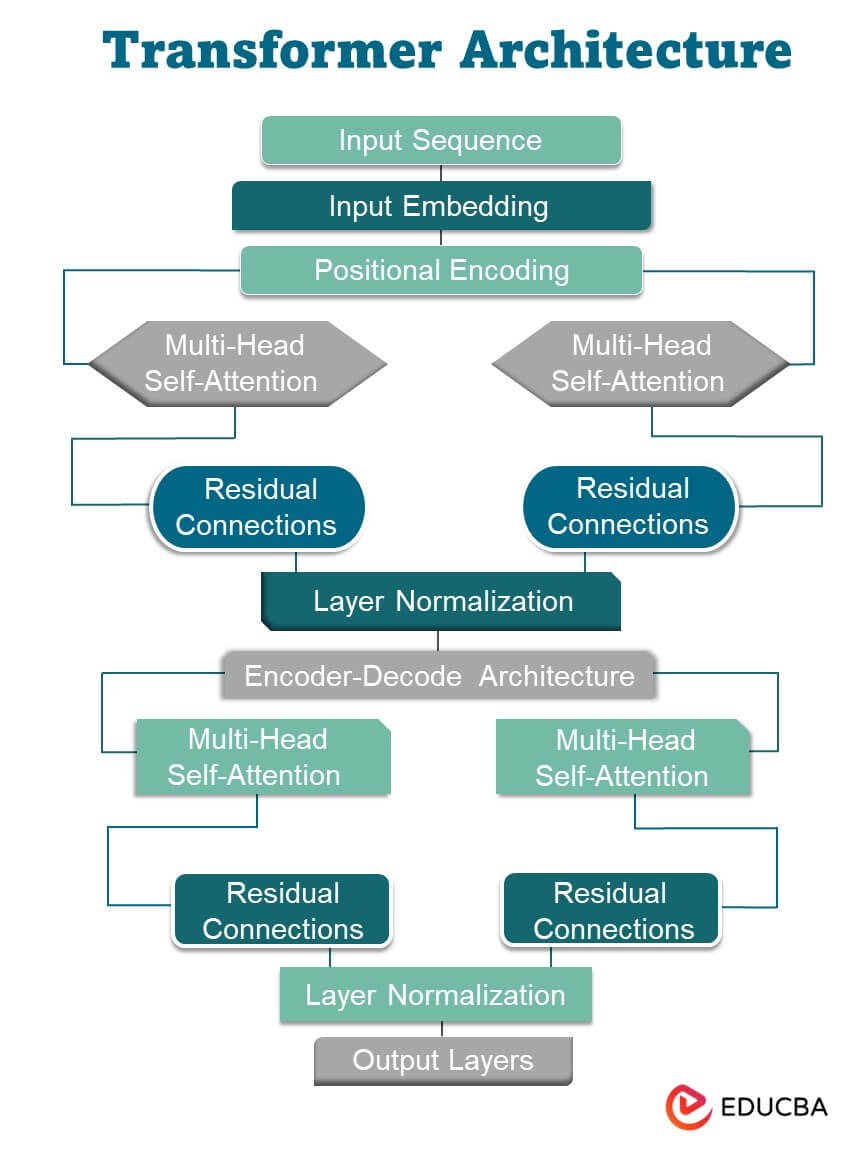
The Transformer architecture is essential for modern deep-learning models, especially in natural language processing. It comprises several critical components:
- Input Embedding: Initially, input sequences are transformed into numerical embeddings, which capture the semantic meaning of words or tokens. These embeddings serve as the model’s input.
- Positional Encoding: Positional encoding is added to the input embeddings to account for the order of words in a sequence. This ensures the model can distinguish between words with the exact embeddings.
- Multi-Head Self-Attention: This is the heart of the Transformer architecture. Self-attention mechanisms enable the model to assign importance to different words in the input sequence, improving prediction accuracy. The “multi-head” aspect involves performing self-attention multiple times in parallel, enabling the model to focus on different parts of the input simultaneously.
- Position-wise Feed-Forward Networks: After the self-attention mechanism, position-wise feed-forward networks are applied independently to each position in the sequence. These networks introduce non-linearity into the model.
- Residual Connections: Residual connections, inspired by the ResNet architecture, help mitigate the vanishing gradient problem during training. They involve adding the input embeddings to the output of the multi-head self-attention and feed-forward network layers.
- Layer Normalization: Layer normalization is used to stabilize training by normalizing the output of each layer. It helps maintain a consistent distribution of activations throughout the network.
- Encoder-Decoder Architecture (Optional): Transformers use an encoder-decoder architecture in sequence-to-sequence tasks, such as machine translation. The encoder processes the input sequence while the decoder generates the output sequence. The encoder’s final hidden state is used to initialize the decoder.
- Output Layers: Different output layers can be added depending on the specific task. For example, a softmax layer is used to predict the next word in a sequence in language modeling.
Self-Attention Mechanism
The self-attention mechanism, a core component of Transformer models, facilitates understanding contextual relationships in data by:
- Calculating attention scores between every pair of elements in a sequence.
- Assigning weights to each element based on its relevance to others.
- Aggregating information by taking a weighted sum of all elements.
- The model can adaptively concentrate on various segments of the input sequence.
- Capturing long-range dependencies without regard to fixed window sizes.
- Enhancing the model’s ability to process sequential data, making it highly effective in NLP tasks.
- Serving as the basis for multi-head attention, a key innovation in Transformer architecture.
Multi-Head Attention
Multi-head attention is a critical component of Transformer models, enhancing their data processing capability by:
- Utilizing multiple sets of weight matrices to perform self-attention in parallel.
- The approach enables the model to concentrate on distinct elements of the input sequence simultaneously.
- Learning diverse, contextually rich representations by capturing various relationships within the data.
- Enhancing the model’s ability to recognize both local and global patterns.
- Combining multiple heads’ outputs to create a more robust and expressive representation.
- Thanks to its versatility and improved attention mechanisms, it enables the model to excel in complex tasks like translation, summarization, and question-answering.
- Leading to more effective and efficient deep-learning models.
Layer Normalization and Residual Connections
Layer Normalization and Residual Connections are two key components in the Transformer model that contribute to its robustness and effectiveness in deep learning tasks:
Layer Normalization:
- It is applied after each sub-layer (e.g., multi-head self-attention and feed-forward layers) within each Transformer layer.
- It helps stabilize the training process by ensuring that the activations in each layer have consistent mean and variance.
- Mitigates the vanishing gradient problem, making it easier to train deep models.
- Enhances the model’s ability to capture meaningful patterns and relationships in the data.
Residual Connections:
- Inspired by the ResNet architecture, residual connections involve adding the input of a sub-layer to its output.
- They create shortcut connections that allow gradients to flow more easily during training.
- Address the vanishing gradient problem, making it feasible to train very deep networks.
- Improve the model’s capacity to learn complex and hierarchical representations.
Transformer Variants
Transformer types have given rise to various variants, each optimized for specialized duties and with distinct architectural innovations. Some notable Transformer variants include:
- BERT (Bidirectional Encoder Representations from Transformers): Pre-trained on large text corpora, BERT captures context bidirectionally, making it robust for NLP tasks.
- GPT (Generative Pre-trained Transformer): GPT models are autoregressive language models that generate text and have achieved state-of-the-art results in tasks like text generation, language translation, and more.
- T5 (Text-to-Text Transfer Transformer): T5 treats all NLP tasks as text-to-text problems, making it highly versatile and effective in various applications.
- RoBERTa (A Robustly Optimized BERT Pretraining Approach): It is an optimized version of BERT with improved training strategies, leading to better performance in NLP tasks.
- XLM (Cross-Lingual Language Model): XLM is designed to understand multiple languages, making it valuable for cross-lingual NLP tasks like translation and sentiment analysis.
- ALBERT (A Lite BERT): ALBERT reduces model size while maintaining performance, making it more efficient for practical use.
- Electra (Efficiently Learning an Encoder that Classifies Token Replacements Accurately): Electra introduces a more efficient pre-training approach by training a model to distinguish between real and generated tokens.
- ViT (Vision Transformer): Applying the Transformer architecture to computer vision tasks, ViT has shown strong performance in image classification and object detection.
- DeiT (Data-efficient Image Transformer): DeiT enhances ViT’s data efficiency, enabling it to achieve high performance with fewer labeled examples.
These variants have pushed the boundaries of what Transformer models can achieve and are often adapted to suit specific use cases in fields such as NLP, computer vision, and more.
Pre-training and Fine-tuning
1. Pre-training:
- This process entails instructing a deep neural network on a substantial, unlabeled dataset to acquire general features and representations.
- Transformer models, like BERT and GPT, are pre-trained on massive text corpora, capturing semantic and contextual information.
- Pre-training typically involves predicting missing words (masked language modeling), generating text, or other unsupervised tasks.
- The text describes a pre-trained model that can be fine-tuned for specific tasks.
2. Fine-tuning:
- After pre-training, the model is adapted with a smaller, task-specific dataset for specific tasks.
- Fine-tuning entails updating the model’s weights while retaining most pre-learned knowledge.
- Task-specific layers and objectives are added, and the model is trained on labeled data for tasks like sentiment analysis, machine translation, or named entity recognition.
- Fine-tuning allows the model to specialize for the particular problem while benefiting from the general knowledge acquired during pre-training.
Pre-training and fine-tuning are crucial for effective transfer learning, making Transformer models highly useful for various NLP and ML tasks.
Transformer model implementations
There are several popular implementations of Transformer models, including:
- Google’s Bidirectional Encoder Representations from Transformers (BERT):
One of the pioneering language models using transformers, BERT excels in understanding bidirectional contexts within text, contributing to various natural language processing tasks.
- OpenAI’s GPT Series (GPT-2, GPT-3, GPT-3.5, GPT-4, ChatGPT)
GPT models, spanning from GPT-2 to GPT-4 and ChatGPT, leverage large-scale transformer architectures for diverse language generation tasks, showcasing advancements in natural language understanding and text generation.
- Meta’s Llama:
A compact model achieving remarkable performance, Llama demonstrates efficiency by matching larger models’ performance in various tasks despite being significantly smaller in size.
- Google’s Pathways Language Model:
A versatile model adept at tasks across multiple domains such as text comprehension, image analysis, and even controlling robotic systems showcasing the breadth of transformer applications.
- OpenAI’s DALL-E:
DALL-E stands out in generating images from text descriptions, showcasing the potential of transformer models in the domain of image synthesis and creative AI applications.
- University of Florida and Nvidia’s GatorTron:
GatorTron specializes in analyzing unstructured medical data from records, paving the way for potential advancements in medical informatics and healthcare data analysis.
- DeepMind’s AlphaFold 2:
AlphaFold 2 revolutionizes the understanding of protein folding, significantly contributing to advancements in biology and drug design by predicting protein structures accurately.
- AstraZeneca and Nvidia’s MegaMolBART:
MegaMolBART generates new drug candidates by leveraging transformer-based models and chemical structure data, contributing to innovation in pharmaceuticals and drug discovery.
Advantages of RNNs and CNNs
Transformers outperform regular Recurrent Neural Networks (RNNs) and Convolutional Neural Networks (CNNs) in various ways:
- Parallelization: Transformers process input data in parallel, allowing more efficient training than RNNs. This results in faster convergence.
- Long-Range Dependencies: The self-attention mechanism enables Transformers to capture long-range dependencies in data, which is challenging for RNNs due to vanishing gradient problems.
- Contextual Understanding: Transformers excel in capturing contextual information, making them highly effective for natural language processing tasks where understanding context is crucial.
- Global Information: Unlike CNNs, which focus on local patterns, Transformers consider the entire input sequence simultaneously, capturing international relationships and improving performance in tasks like sequence-to-sequence learning.
- Scalability: Transformers scale well to handle short and long sequences without the performance degradation often observed in RNNs and CNNs.
- Ease of Training: The attention mechanism reduces the likelihood of vanishing or exploding gradients, simplifying training compared to the challenges associated with training deep RNNs.
- Versatility: Transformers are versatile and applicable to various tasks without significant architectural changes, facilitating transfer learning and adaptation to different domains.
- Interpretable Representations: The attention mechanism in Transformers provides interpretability, allowing for a better understanding of how the model processes input data compared to the more opaque internal representations of RNNs.
Challenges and Limitations
- Computational Resources: Training and using large Transformer models demand substantial computational power and memory, limiting accessibility for many researchers and applications.
- Data Requirements: Pre-training often requires massive datasets, making it impractical for low-resource languages and specialized domains.
- Model Size: Larger models may perform better but are challenging to deploy on resource-constrained devices or in real-time applications.
- Interpretability: Understanding how transformers make predictions can be challenging due to their “black-box” nature.
- Fine-tuning Challenges: Proper fine-tuning for specific tasks can be non-trivial and requires careful selection of hyperparameters and training procedures.
- Lack of Common Sense Understanding: Transformers may need help with commonsense reasoning and may provide plausible-sounding but incorrect answers.
- Bias and Fairness: Models trained on biased data may produce biased or unfair outputs, necessitating careful data curation and bias mitigation strategies.
- Ethical Concerns: The capabilities of large language models like GPT-3 raise ethical concerns about misuse, misinformation, and deepfakes.
Future Directions
- Efficiency: Research will focus on making Transformer models more computationally efficient and environmentally friendly.
- Multimodal Integration: Transformers can now process and understand multiple data types, including text, images, and audio.
- Interdisciplinary Applications: Transformers address complicated issues in various fields, including healthcare, finance, and climate science.
- Ethical AI: Addressing ethical concerns, like bias, fairness, and transparency in model decision-making.
- Zero-shot Learning: Enhancing models’ generalization abilities to new tasks without extensive fine-tuning.
- Interpretable AI: Developing methods to make Transformer models more interpretable and explainable.
- Quantum Computing: Exploring how quantum computing can enhance the training of Transformers for complex tasks.
Conclusion
Transformer models have revolutionized the field of artificial intelligence, particularly in natural language processing. Their innovative architecture, incorporating self-attention mechanisms, multi-head attention, and efficient training techniques, has unlocked unprecedented capabilities in understanding and generating complex data. While they have demonstrated exceptional success in various applications, their continued evolution promises greater versatility and efficiency. Transformer models have paved the way for transfer learning and interdisciplinary advancements, but they also bring forth challenges, such as computational demands and ethical considerations. In the future, addressing these challenges and harnessing the potential of Transformers will be paramount for further progress in AI.
Recommended Articles
We hope that this EDUCBA information on “What is a Transformer Model” was beneficial to you. You can view EDUCBA’s recommended articles for more information,
