Updated November 21, 2023
Definition of Web Crawler Java
A web crawler, also known as a spider or a web spider, is a software program or automated script that systematically browses the internet, typically for the purpose of indexing and collecting information from websites. It operates by following hyperlinks from one web page to another, retrieving data and metadata, such as URLs, text content, images, and other resources. Search engines like Google use web crawlers to continuously scour the web, gathering information to create searchable indexes and provide relevant results to user queries.
Table of Contents
- Definition of Web Crawler Java
- Why use Java for web crawling?
- How to build a web crawler in Java?
- Examples
- Key Differences Between Data Crawling vs. Data Scraping
- Considerations and Best Practices
Key Takeaways
- Automated software navigating the internet
- Systematically visits web pages
- Collects data and metadata
- Follows hyperlinks to explore content
- Used by search engines for indexing
- Gathers information for search results
Why use Java for Web Crawling?
There are several reasons to use Java for web crawling:
- Robustness: Java is known for its stability and reliability. It provides a strong foundation for building complex web crawling systems that can handle large amounts of data and handle various types of websites.
- Extensive Libraries: Java offers a wide range of libraries and frameworks specifically designed for web crawling and scraping, such as Jsoup, HttpClient, and Selenium. These libraries simplify tasks like fetching web pages, parsing HTML, handling HTTP requests, and extracting data.
- Multithreading: Java’s multithreading capabilities allow for concurrent processing, making it easier to crawl multiple web pages simultaneously. This improves the efficiency of the web crawling process, reducing the time required to fetch and process data.
- Ecosystem: Java has a mature and extensive ecosystem of tools, frameworks, and libraries that can be leveraged for web crawling purposes. This makes integrating with other technologies and systems easier, such as databases, data processing frameworks, or API integrations.
- Cross-platform Compatibility: Java’s “write once, run anywhere” principle allows web crawlers built in Java to run on different operating systems without major modifications.
How to Build a Web Crawler?
To build a web crawler in Java, you will need to use the following libraries:
- net: This library provides a low-level API for connecting to websites and downloading their content.
- jsoup: This library provides a high-level API for parsing HTML content.
- jsoup.select.Elements: This library provides a class for selecting elements from a parsed HTML document.
The following steps are involved in building a web crawler in Java:
- Create a new Java class called MyWebCrawler.
- Import the necessary libraries into your Java class.
- Create a method called crawl() that takes a URL as input and returns an HTML document.
- In the crawl() method, use the java.net library to connect to the URL and download the HTML content.
- Use the jsoup library to parse the HTML content and extract the links from the page.
- For each link, check if the link has already been visited. Call the crawl() method to crawl the page if the link has not been visited.
Example of Web Crawler Java
Below are the different examples of web crawlers in Java:
Example #1
Code:
import java.io.IOException;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class WebCrawler {
public static void main(String[] args) {
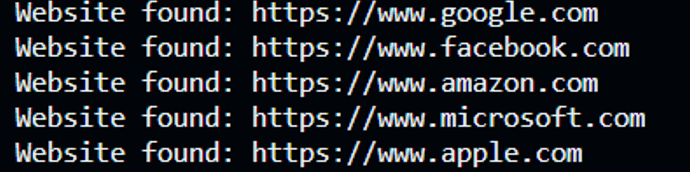
String url = " https://www.google.com"; // Website URL to crawl
int maxDepth = 3; // Maximum depth to crawl
crawl(url, 0, maxDepth);
}
public static void crawl(String url, int depth, int maxDepth) {
if (depth > maxDepth) {
return;
}
try {
Document document = Jsoup.connect(url).get();
System.out.println("Crawling: " + url);
// Extract and process the data from the web page
// Example: Print the page title
String title = document.title();
System.out.println("Title: " + title);
// Find and process links on the page
Elements links = document.select("a[href]");
for (Element link : links) {
String nextUrl = link.attr("abs:href");
crawl(nextUrl, depth + 1, maxDepth);
}
} catch (IOException e) {
System.err.println("Error crawling: " + url);
e.printStackTrace();
}
}
}Output:
Example #2
This example starts with the Wikipedia main page (https://en.wikipedia.org/wiki/Main_Page). The crawl() method fetches the web page, extracts information, and prints the title and links.
Code:
import org jsoup jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
public class WikipediaWebCrawler {
public static void main(String[] args) {
String url = "https://en.wikipedia.org/wiki/Main_Page"; // Starting URL
crawl(url);
}
public static void crawl(String url) {
try {
Document document = Jsoup.connect(url).get();
// Extract information from the current page
String title = document.title();
System.out.println("Title: " + title);
Elements links = document.select("a[href]");
// Print all the links on the current page
for (Element link : links) {
String href = link.attr("href");
System.out.println("Link: " + href);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}Output:

Example #3
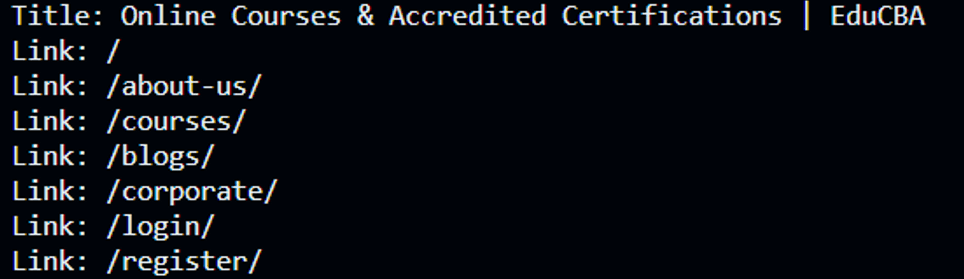
In this example, we connect to the EduCBA website (https://www.educba.com) and retrieve the HTML content using the Jsoup.connect(url).get() method. We then extract the page’s title using document.title() and print it. Additionally, we select all the anchor tags with an href attribute using the document.select(“a[href]”) and print their links.
Code:
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import java.io.IOException;
public class EduCBAWebCrawler {
public static void main(String[] args) {
String url = "https://www.educba.com"; // Specify the URL to crawl
try {
Document document = Jsoup.connect(url).get();
// Extract information from the current page
String title = document.title();
System.out.println("Title: " + title);
Elements links = document.select("a[href]");
// Print all the links on the current page
for (Element link : links) {
String href = link.attr("href");
System.out.println("Link: " + href);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}Output:
Key Differences Between Data Crawling vs. Data Scraping
| Section | Data Crawling | Data Scraping |
| Definition | Automated process of navigating through websites and extracting specific data. | Extracting data from websites by parsing the HTML structure |
| Purpose | Discover and collect data from various sources | Extract specific data from targeted websites |
| Scope | Broad and comprehensive data collection | Targeted data extraction from specific websites |
| Method | Automated web crawling using bots or spiders | Parsing HTML structure using scraping tools or libraries |
| Data Volume | Large-scale data collection | Variable, depending on the targeted data |
| Data Format | Extracts data in various formats (HTML, XML, JSON, etc.) | Extracts data in structured formats (CSV, Excel, databases, etc.) |
| Complexity | More complex due to the need to handle dynamic websites and javascript | Relatively simpler as it focuses on specific elements |
Understanding the Differences
Data crawling and data scraping are both techniques used to gather information from the internet. While they are often used interchangeably, the two have some key differences.
Data crawling is the process of automatically discovering and exploring data sources, such as websites, databases, and social media platforms. It is typically used to index data sources for search engines, track the spread of information, and discover new content. Data crawlers follow links or other navigational cues to navigate through different data sources and collect information about the data they encounter.
On the other hand, data scraping is the process of extracting specific data from data sources. It is typically used to collect research, analysis, and price comparison data. Data scrapers use techniques like HTML parsing, regular expressions, and APIs to identify and extract data from data sources. The extracted data can then be stored in a database, spreadsheet, or other format for further analysis.
Considerations and Best Practices
When building a web crawler in Java, it’s important to consider the following considerations and best practices:
- Respect Website Policies: Adhere to website policies, including terms of service, robots.txt files, and any specified crawling limitations. Avoid overloading servers by implementing appropriate delays between requests.
- Throttling: Implement a mechanism to limit the number of requests per second to prevent overwhelming the target website and to avoid being banned or blocked. Respect server response codes, such as 429 (Too Many Requests) and 503 (Service Unavailable).
- User-Agent String: Set a user-agent string in the HTTP request headers to identify the crawler and provide contact information for the website owner to reach you if necessary.
- Handling Redirects: Handle redirects properly by following them and updating the URL accordingly. Consider different types of redirects like 301 (Permanent Redirect) and 302 (Temporary Redirect).
- Error Handling: Implement robust error handling of network failures, invalid URLs, and other exceptions. Log errors and handle them gracefully to ensure the stability of the crawler.
- Duplicate URL Avoidance: Keep track of visited URLs to avoid revisiting them. Use a data structure like a HashSet or a Bloom to efficiently check if a URL has been visited before.
- Politeness and Crawling Etiquette: Be a good web citizen by implementing politeness mechanisms. Respect website bandwidth, server load, and crawling speed. Consider implementing a crawl delay between requests to avoid overloading servers.
- Handling Different Content Types: Consider handling different content types, such as HTML, XML, JSON, or binary files. Use appropriate libraries and parsers for each type to extract relevant information effectively.
- Data Storage and Processing: Decide how to handle the extracted data. You can store it in a structured format like a database, save it to files, or perform real-time processing as required.
- Testing and Monitoring: Thoroughly test the crawler on different websites and monitor its behavior. Monitor resource usage and crawling speed, and ensure proper handling of edge cases and exceptions.
Conclusion
Creating a Java-based web crawler demands careful attention to factors like respecting website policies and implementing mechanisms for server politeness. Error handling, duplicate URL management, and data processing methods are vital. Testing and monitoring ensure a reliable, well-mannered crawler that extracts data efficiently while fostering positive relations with website owners.
FAQs
Q1. How can I implement a web crawler in Java?
Answers: Java provides libraries like JSoup for web crawling. You can use these libraries to connect to web pages, extract data, and follow links. You can build a web crawler in Java by recursively crawling pages and processing the data.
Q2. What are some challenges in web crawling?
Answers: Challenges in web crawling include handling dynamic content, JavaScript rendering, CAPTCHAs, AJAX requests, handling different content types (HTML, XML, JSON), and dealing with websites with complex navigation structures.
Q3. What can I do with the data obtained from a web crawler?
Answers: The data obtained from a web crawler can be used for various purposes, such as:
- Building search engine indexes
- Analyzing website structures and link patterns
- Extracting specific information from web pages
- Monitoring website changes or updates
- Gathering data for research or data analysis purposes
Q4. Are there any legal or ethical considerations when using a web crawler?
Answers: Yes, it is essential to respect the legal and ethical considerations when using a web crawler. Some websites may have terms of service that restrict or prohibit crawling. Always seek permission or ensure that your crawling activities comply with the website’s terms of service. Additionally, be mindful of data privacy and avoid crawling or accessing sensitive or personal information without proper authorization.
Q5. How can I handle data storage and processing in a web crawler?
Answers: You can store the extracted data in a database, save it to files, or process it in real-time using Java’s database libraries (e.g., JDBC) or frameworks like Apache Kafka or Apache Spark.
Recommended Articles
We hope that this EDUCBA information on “Web Crawler Java” was beneficial to you. You can view EDUCBA’s recommended articles for more information.

