Updated March 23, 2023

Introduction to Data Engineering
Data Engineering is the practice of Data processing, data cleaning and preparing ready to use data for analytics, data science, and Artificial intelligence implementation. This is mainly related to data infrastructure ETL and ELT pipeline development activities for machine learning and data quality checks and data pipeline deployments. The role of a Data engineer is complementing the data scientist or analyst professionals to build and implement a data-driven solution framework.
Need for Data Engineering
It is important to understand why we need data engineering. For a business point of view.
- It is a technology stack.
- The associated workforce to support data science projects.
- The setup which helps the data-driven business decision.
- Applying Data models to create predictive and prescriptive analytics to business for better outcomes.
How does Data Engineering Work?
Organizations that implement data science or analytics projects prefer to include skilled data engineering professionals in the team. Based upon data architects’ recommendations data engineers use various tools and technologies for the following activities which are part of their job responsibilities.
- Configure connections to data sources.
- Datastore setup for staging and process data storage.
- Retrieving data from sources
- storing high volumes of data
- Data quality and wrangling
- processing to generate standardized data
- configuring and maintaining data pipelines
- batch and real-time stream data processing
Data engineering relies upon several big data technologies, Following is a list of tools or technologies which are included as a part of industry best practices.
- Hadoop cluster, Apache Spark, Splunk, Apache Flink, Azure HDinsight.
- NoSQL data stores like Apache Cassandra database, MongoDB.
- In-memory cache databases like Redis, SAP HANA.
- Data processing tools such as Apache Kafka, Apache NiFi, Informatica Cloud services.
- Cloud-based tools like ASES data pipelines, Google Big Query, and Azure Data Factory.
- Standard RDBMS and file systems.
- Various OS-specific scripting like Linux Shell scripting, windows batch, and Power shell scripting.
- Cloud storage like S3.
- API based tools like AWS API gateway to prevision the data APIs for Souring data and deploying analytics
- Time series data stores.
- IoT specific tools like Node-Red.
There are several standard ETL tools and big data tools along with scripting languages like python, SQL is part of the data engineering framework. The professionals usually work with multiple skill sets to achieve building the data pipelines. DevOps Specialist is also part of the team to manage the scalable infrastructure and microservices-based data APIs management.
Apart from data-related tools data engineers are also familiar with the BI tools like Tableau, MS Power BI to assist the BI professionals to provide the appropriate format and structure of data.
The data engineers are also familiar with Cloud-based tools and DevOps tools like Jenkins and Docker to create efficient implementations.
Data engineering as we discussed so far related to tools and technology aspects of the data science or analytics project framework, whereas feature engineering is another associated practice which deals with data and business domain for feature selection based upon the business use case scenarios which are managed by data analysts and data scientists in the organization.
Scope of Data Engineering
The Scope of data engineering mostly involves the pre-processing of data which reduces the overheads for data scientists and analysts for data preparation stages. To understand it better following is a high-level framework overview of the data engineering setup for data science.
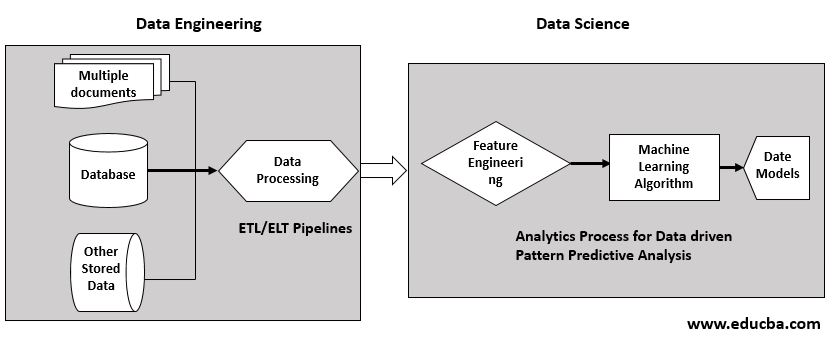
In the diagram shown Data engineering is the first phase that links to Data science as the second phase.
- It collects raw data from various source applications, file systems, IoT sensors, and other file storage through ETL(Extract Transform, Load) or ELT(Extract, Load, Transform) pipeline.
- ETL is mainly for the implementation of the data warehouse, whereas ELT is for Big data frameworks.
- Data engineering includes data quality processes and transformation techniques.
- Store the pre-processed data in the data warehouse or data lakes for subsequent use.
- The set up provides input data to the Data Science framework.
- Data Analyst and Data Scientists do initial exploratory analysis for the feature engineering process.
- The data helps to generate Business Intelligence reports and charts apart from machine learning applications.
- Feature engineering is an iterative process to further optimize the data set to be processed by Machine learning.
- Data scientists apply several machine learning models iteratively to generate a best-fit Machine learning model for the use case.
- The input data is helpful to train and test the model while developing.
Advantages
Let’s discuss some of the major advantages:
- It helps to pre-process data of various formats and various heterogeneous sources to a standard format and structure.
- Automate the pipeline for incremental data or the latest data to be used by the analytics solution by implementing automation tools for batch processing and scheduling.
- Real-time analytics support by data engineering by using the latest and best practices, technologies like Apache Kafka, Spark, and data-bricks.
- Applying the governance policies and security compliance of data by masking and encrypting the confidential information by applying various business rules.
- Creating production-ready data for faster completion of analytics project implementations.
- Customization of the data structure by joining and wrangling data to be best for the machine learning algorithm needs to be based upon the data scientist’s recommendation.
Target Audience
- The target audience for data engineering is business stack holders which apply analytics for business processes.
- The AI Application developers, who need adequate data for building efficient cognitive solutions.
- The Data analysts professional who are generally involved in Exploratory data analysis using the raw data.
- Data scientists who use the data to develop and deploy machine learning models for business.
Conclusion
It is a crucial part of successful data science and analytics implementation. The types of tools and technologies are evolving with time. There are several new technologies are introduced to augment the efficiencies, latency, process, and outcomes. Additionally, the cloud and Artificial Intelligence trends in the industry create more demand for data engineering practices and encourage the existing and new IT professionals to get the associated skills and upgrade their job profiles.
Recommended Articles
This is a guide to What is Data Engineering?. Here we discuss how do Data Engineering works? Need and Scope along with the advantages. You may also look at the following articles to learn more –

