Updated April 18, 2023

Introduction to XML parsing in Python
Python provides different kinds of functionality to the user, in which XML parsing is one of the functionalities provided by Python. XML means Extensible Markup Language and the main use of XML is for the web page. Basically, python allows us to parse the XML document by using two different modules that we called as xml.etree and Element Tree module. Normally parsing means it reads the data from the different files and splits it into the different pieces that are the XML file. Therefore, we need to use different elements such as Tags, Text strings, Attributes, Tail Strings, etc.
What is XML parsing in Python?
Now let’s see what XML parsing is in Python as follows. Basically, XML parsing is used by data scientists, so we must understand what web scraping is and the general structure of parsing.
Parsing intends to peruse data from a record and split it into pieces by recognizing portions of that specific XML document. How about we continue on further to perceive how we can utilize these modules to parse XML information.
xml.etree.ElementTree Module
This module assists us with designing XML information in a tree structure which is the most normal portrayal of progressive information. Furthermore, component type permits stockpiling of various levelled information structures in memory and has the accompanying properties:
- Tag: Basically, it represents the string and which type of data to store.
- Attributes: The attributes are used to identify how many attributes are stored as a dictionary.
- Text String: Whatever information we need to display that we store into the Text String.
- Tail String: If required, then we can also use tail string.
- Child Element: It is used to store the number of child elements to store as a sequence.
ElementTree is a class that wraps the component structure and permits transformation to and from XML. Allow us presently to attempt to parse the above XML document utilizing the Python module.
Processing XML in Python
Now let’s see how we can process the XML file in Python as follows.
The Python standard library gives a negligible yet valuable arrangement of interfaces to work with XML.
The two generally fundamental and extensively utilized APIs to XML information are the SAX and DOM interfaces.
This is valuable when your archives are enormous or have memory impediments; it parses the document as it pursues it from the circle, and the whole record is never put away in memory.
Archive Object Model (DOM) API − This is a World Wide Web Consortium suggestion wherein the whole record is added something extra to memory and put away in a progressive (tree-based) structure to address every one of the components of an XML report.
SAX clearly can’t handle data as quickly as possible when working with enormous documents. But then again, utilizing DOM only can truly kill your assets, particularly whenever utilized on a ton of little documents.
SAX is perused just, while DOM permits changes to the XML record. Since these two distinct APIs in a real sense complete one another, there is no motivation behind why you can’t utilize them both for huge undertakings.
E.g.:
<collection year=2021>
<student Name = "Jenny">
<class> SE</class>
<dept>COMP</dept>
<roll_no>25</roll_no>
</student>
</collection>Parsing XML with SAX APIs
SAX is a standard interface for occasion-driven XML parsing. Your ContentHandler handles the specific labels and properties of your flavor(s) of XML. A ContentHandler object gives techniques to deal with different parsing occasions. Its parser calls ContentHandler techniques as it passes the XML document.
The techniques start to document and end documents are called toward the beginning and the finish of the XML document. The strategy characters(text) is passed character information of the XML document by means of the boundary text.
The ContentHandler is called toward the beginning and end of every component. On the off chance that the parser isn’t in namespace mode, the strategies startElement(tag, traits) and endElement(tag) are called; something else, the comparing techniques startElementNS and endElementNS are called. Here, the tag is the component tag, and characteristics are an Attributes object.
Create XML file using ElementTree
Now let’s create XML files using ElementTree as follows.
First and foremost, we need to import ‘xml.etree.ElementTree’ for making a subtree. From that point onward, we make the root component, and that root component ought to be in an expected square; in any case, the blunder will emerge. However, in the wake of making the root component, we can make a tree structure without any problem. Then, at that point, the document will be put away as ‘name you need to provide for that file.xml’. ElementTree is a significant Python library that permits you to parse and explore an XML record.
Example of XML parsing in Python
Code:
import xml.etree.ElementTree as ett
def createXML(XML_fileName) :
root = ett.Element("college")
m1 = ett.Element("depatment")
root.append (m1)
b1 = ett.SubElement(m1, "Name")
b1.text = "Comp"
b2 = ett.SubElement(m1, "class")
b2.text = "SE"
m2 = ett.Element("department")
root.append (m2)
c1 = ett.SubElement(m2, "Name")
c1.text = "Comp"
c2 = ett.SubElement(m2, "Class")
c2.text = "TE"
tree = ett.ElementTree(root)
with open (XML_fileName, "wb") as files :
tree.write(files)
if __name__ == "__main__":
createXML("College.xml")Explanation:
After execution of the above code, it generated an XML file. The Final output of code we illustrated by using the following screenshot as follows.
![]()
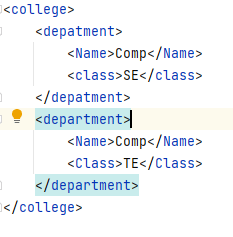
parse XML file
Now let’s see how we can parse the XML file in python as follows.
There are two methods to parse the XML file as follows.
First by using minidom:
Here we use an already created XML file that is college.xml, as shown in the above screenshot.
import xml.dom.minidom
def main():
document = xml.dom.minidom.parse("college.xml")
print(document.nodeName)
print(document.firstChild.tagName)
if__name__ = "__main__"
main();Explanation
In the above example, we use the minidom method to parse the XML file. The Final output of code we illustrated by using the following screenshot as follows.

So in this way, we can parse all elements from the XML file as per our requirement.
Now let’s see how we can parse the XML file by using ElementTree as follows.
Example
import xml.etree.ElementTree as ETE
tree_element = ETE.parse('college.xml')
root = tree_element.getroot()
print('Records from XML file:')
for element in root:
for subelement in element:
print(subelement.text)Explanation
The Final output of the code we illustrated by using the following screenshot as follows.

Conclusions
We hope from this article you learn more about XML parsing in python. From the above article, we have taken in the essential idea of XML parsing in python, and we also see the representation of the XML parsing. From this article, we learned how and when we use XML parsing in python.
Recommended Articles
We hope that this EDUCBA information on “xml parsing in python” was beneficial to you. You can view EDUCBA’s recommended articles for more information.
