Updated April 4, 2023

Definition of XPath text
XPath text() function is a built-in function of the Selenium web driver that locates items based on their text. It aids in the identification of certain text elements as well as the location of those components within a set of text nodes. The elements that need to be found should be in string format. The text of the web element is used by the function to locate the element on the webpage. This function comes in handy if your element contains text, such as labels, which always have static text.
Syntax:
The text() function in XPath has the following syntax:
//tag_name[text()='any text content']
where the text() method compares the value to the string provided on the right side and returns the text of the web element indicated by the tag name.
How does XPath text works?
Finding the nearest unique web element to your target web element is the first step in developing XPath. With XPath, data can be extracted based on the contents of text elements rather than the page structure. So, if we’re scraping the web and come across a website that’s difficult to scrape, XPath might just rescue the time.
Let’s take an XML code like this:
<class>
<std>Welcome</std>
<next>
Welcome
</next>
<sample>Well, <nested> I am so interested </nested>.</sample>
</class>
The Xpath Expression is given as
//*text()= ‘Welcome’
This would return an element <std> Welcome </std> but not <next> element. This is due to the presence of whitespace around the greeting text in the <nex> element. To display both next and std element we shall use the expression like
//*[normalize-space(text()) = 'Welcome']
While doing the comparison, this command will trim the surrounding whitespace. When using normalize-space, we can observe that the text() node specifier is optional.
The contains function can be used to locate an element that includes certain text. The <example> element will be returned by the following expression:
//sample [contains (text(), 'Welcome')]
XPath using a text of child
Xpath: //div/a[text()=’Use Custom Domain?’]
Select the immediate parent of the div> element that also has <a> as a direct child and some text attached to it.
Note: If the div> element is immediate parent, /parent::* or /parent::div will return the same element; otherwise, no element will be discovered.
Xpath: //div/a[text()=’Use Custom Domain?’]/parent::*
Or
Xpath: //div/a[text()=’Use Custom Domain?’]/parent::div
Or
Xpath: //div/a[text()=’Use Custom Domain?’]/..
Or
Xpath: //div/a[.=’Use Custom Domain?’]/..
Assume that the web element you’re looking for is in the Panel Table and has some common text.
Begin by creating a panel with a single attribute, in this example ‘TITLE.’
/*[@title='Armaedan Book']
Go through all of the table tags now.
/*[@title='Armaedan Book']
/table
Find the column with the text ‘Name' in all of the tables.
The final XPath would look like this:
/*[@title='Armaedan Book']*[@title='Armaedan Book']*[@title
Using Attributes with a Text
//*[@id='user-id']
/following-sibling::ul/descendant::a[text()='password']
With header, a text() looks like
//h3[text()='Title’]
Let’s have a look at the website “https://salesforce.com/text-box” and use the text() function to find the “Email” label. We’ll recognize the element by looking at the text in the user interface. The UI text is “Email,” and the same is true for the element tag, i.e… As a result, the label element’s XPath Expression will be:
/label [text() =”Email”]
Rather than using the attribute and values to identify the element, we used the text on the web page to do so.
Examples
The text() node should have a direct relationship within an element. In the next section, we are going to look at an example in different cases of how a text() act in an Xpath.
Example #1: Accessing the yahoo website
Go to the yahoo homepage and right-click the button ‘Forgot username’. We could find Inspect, click it. It automatically directs to a window with an element where we could see different elements and their actions. to move to the Xpath tab press Ctrl+F to find the matching node. The sample snapshot is given below:
Output:
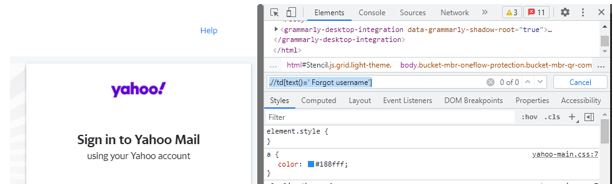
.//td[text()=' Forgot username']
Next Exploring Selenium Website. Perform the above-defined Steps to find the Xpath. The sample Text of span is identified.
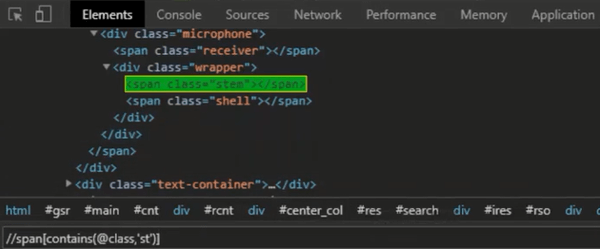
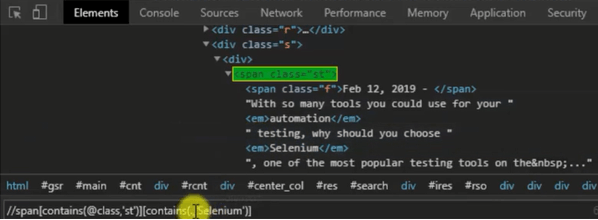
Example #2
hs.html
<html>
<body>
<ul>
<li>Song 1</li>
<li>Song 2 with <a href="...">Track</a></li>
<li>Song 3 with <a href="...">Hollywood</a></li>
<li><h2>Song 4 theme</h2> ...</li>
</ul>
</body>
</html>
XPath Expression
//li[ a/text()="Track" ]
Explanation
The above script identifies the text with the name ‘Track’ which is defined in Xpath Expression.
Output:
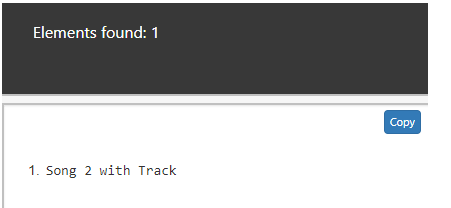
Example #3
<!DOCTYPE html>
<html lang="en">
<head>
<title>Ordered list-HTML</title>
</head>
<body>
<p> EDUCBA HTML List Tutorial:</p>
<ol>
<span style="font-weight: 400;"/>
<li value="5" >xpath list</li>
<li>Texas</li>
<li><h2>Title of the page</h2> ...</li>
<li>Arizona
<ol type="i" >
<li> <i>Nation Availability</i></li>
<li><i>Countries List</i></li>
<li><i> Coldest State</i> </li>
</ol>
</li>
<li>Snapshots</li>
</ol>
</body>
</html>
Xpath Expression
//li[ 5 ]/h2[ text() = "Title of the page" ]
Explanation
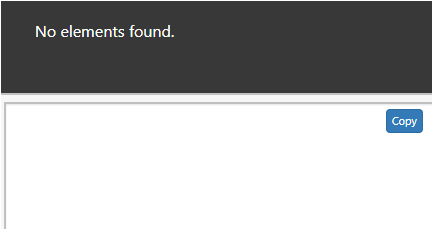
The above script identifies the text with ’Title page’ which is defined in Xpath Expression. The path is not identified with the <h2> therefore it shows No elements.
Output:
Example #4: Using Java XML
<?xml version="1.0" encoding="UTF-8"?>
<Website> EDUCBA
<Table1>Java</Table1>
<Table2>
<Course1>Learning Java</Course1>
<Course2>Learning Exception</Course2>
<Course3>Learning Database handling</Course3>
<Course4>Learning Strings</Course4>
</Table2>
<Table3>css</Table3>
<Table4>javascript</Table4>
<Table5>ajax</Table5>
<Table6>php</Table6>
<Table7>mysql</Table7>
<Table8>python</Table8>
</Website>
The Xpath Expression is given as
XPathExpression exq= xpath.compile("//Website[@Table1='Java’]/name/text()");
String cricketer = (String) exq.evaluate(doc, XPathConstants.STRING);
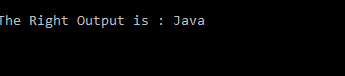
System.out.println("The right Output is : " + Website);
Output:
Example #5: Contain using python
from selenium import webdriver
#set chromodriver.exe path
driver = webdriver.firefox(executable_path="C:\\firefoxdriver.exe")
driver.implicitly_wait(0.8)
driver.get("https://www.educba.com/about/about_blog.htm")
l = driver.find_element_by_xpath("//a[text()='Privacy Policy']")
m = driver.find_element_by_xpath("//a[contains(text(), 'Privacy')]")
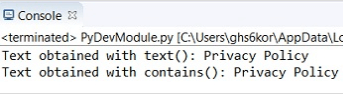
print('content obtained with text(): ' + l.text)
print('content obtained with contains(): ' + m.text)
driver.quit()
Explanation
With the Selenium web driver in Python, we may use the XPath to find an element that contains specific content. This locator includes features that aid in the verification of specific text within an element. Initially, we had set a driver.exe and followed by launching an URL. The element text is retrieved using the variable along with the function text() and contains (). Therefore, an Output is shown as below.
Output:
Conclusion
It all boils down to how well you comprehend and evaluate the code when it comes to developing a good XPATH. The greater understanding of the code, the more options we’ll have for constructing successful XPATHs. Now, even after employing the above capabilities, there may be occasions when the user is unable to discover the site parts uniquely. The XPath axes come to the rescue in these situations, assisting in the location of a web element.
Recommended Articles
This is a guide to XPath text. Here we discuss the definition, syntax, How does XPath text works? examples with code implementation. You may also have a look at the following articles to learn more –
