Updated June 28, 2023

Definition oF XSLT Tokenizes
XSLT tokenize is defined as breaking a declared string with one more delimiter character by treating each token as a node with <token> element and a part of XSLT2.0. A tokenizer splits up a string based on a regular expression. It returns a node set of token individual elements and loops over it by changing the document profile.
Syntax:
The XSLT syntax is defined as
<xsl:call-template name="str:tokenize">
<xsl:with-param name="element" select="stringval" />
<xsl:with-param name="entitycharac" select="stringval" />?
</xsl:call-template>
The tokenize function takes two parameters. First, a list of values is assigned in the input file, and the last is the delimiter character.
How does the Tokenize function work in XSLT?
A pure XSLT deals with tokenization. Let’s take a case where we have a comma in a list of values in a single element within the declared XML file; there is no proper way to neglect those in a Map Process; there pays a way for tokenization. The tokenize function checks a sequence of strings from an input file by breaking at any delimiting sub-part. This function can also be used other than a comma (like the semicolon, *). A few Path examples of evaluating tokenize in a string are listed here:
| tokenize( ‘m n o’, ‘\s’) | (‘m’, ‘n’, ‘o’) |
| tokenize( ‘m n o’, ‘\s’) | (‘m’, ”, ”, ‘n’, ‘o’) |
| tokenize( ‘m n o’, ‘\s+’) | (‘m’, ‘n’, ‘o’) |
| tokenize( ‘ m n’, ‘\s’) | (”, ‘m’, ‘n’) |
| tokenize( ‘m,n,o’, ‘,’) | (‘m’, ‘n’, ‘o’) |
| tokenize( ‘m,n,,o’, ‘,’) | (‘m’, ‘n’, ”, ‘o’) |
| tokenize( ‘2005-10-21T11:14:00’, ‘[\-T:]’) | (‘2006′, ’12’, ’25’, ’12’, ’15’, ’00’) |
| tokenize( ‘this, dog.’, ‘\W+’) | (‘this ‘, ‘dog ‘,”) |
| tokenize( (), ‘\s+’) | () |
| tokenize( ‘mno’, ‘\s’) | mno |
When we tokenize a comma or space, then they are combined into one single expression like this:
<xsl:for-each select="tokenize(., ',|\s')">
Tokenizing a number with a string gives the result as
tokenize ("11, 13, 22, 60", ",\s*")
Output is
("11", "13", "22", "60")
The Tokenize() processing of various XML files has made the code run faster, and its output is a nice mark-up. Let’s see a crisp example now. For example, if we have a source statement like:
tokenize (‘2002-05-02T12:30:23’, ‘-T:’) The following nodeset consists of :
<token>2002</token>
<token>05</token>
<token>02</token>
<token>12</token>
<token>30</token>
<token>23</token>
The first argument within the quotes is tokenized and evaluated into the individual set. The last argument is omitted with the whitespaces.
Examples of XSLT Tokenizes
A simple XML file we are going to process
Example #1
<?xml-stylesheet type="text/xsl" href="simple.xsl"?>
<eatables>
<types>Vegetables, Fruits, Nuts</types>
</eatables>
Next is the XSL stylesheet needed to do transformation
<?xml version="1.0" encoding="UTF-8" ?>
<xsl:stylesheet version="1.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="xml" indent="yes"/>
<xsl:strip-space elements="*" />
<xsl:template match="/">
<Grocelist>
<xsl:apply-templates select="eatables/types"/>
</Grocelist>
</xsl:template>
<xsl:template match="types">
<xsl:call-template name="tokenize">
<xsl:with-param name="aaa" select="." />
</xsl:call-template>
</xsl:template>
<xsl:template name="tokenize">
<xsl:param name="aaa" />
<xsl:variable name="pref1" select="normalize-space(
substring-before( concat( $aaa, ','), ','))" />
<xsl:if test="$pref1">
<first>
<xsl:value-of select="$pref1" />
</first>
<xsl:call-template name="tokenize">
<xsl:with-param name="aaa" select="substring-after($aaa,',')" />
</xsl:call-template>
</xsl:if>
</xsl:template>
</xsl:stylesheet>
Explanation
The stylesheet has a template match that matches the<eatables> element in the XML, and it reads the content to the variables declared in the stylesheet and then creates a tokenized variable that collects the list of the variable with commas. Finally, it is returned to the Output document as:
Output:
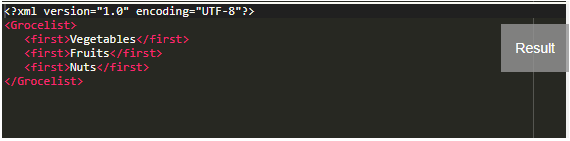
Example #2
Next XML file takes a Stocking database, and we going to process
<?xml version="1.0" encoding="iso-8859-1"?>
<service>
<stock name="europe">AU8702 -e -Ss country/AU8702pfb_AU -pf AU8702_AG</stock>
<stock name="e-exchange">
e231 1112 240 6,703.83.99999 Cango 921 37 -4.8 0.0325 update fiber index
e342 5214 514 5,972.15.99900 Navios 1005 26 -5.1 0.5558 regular internet FT100
e440 214 214 10,950.87.00000 Maritime 718 55 -1.2 0.7886 regular net Euronext100
</stock>
</service>
XSL
<?xml version="1.0" encoding="ISO-8859-1"?>
<xsl:stylesheet version="2.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output method="xml" version="1.0" encoding="UTF-8" indent="yes" />
<xsl:template match="/">
<volume>
<xsl:apply-templates select="/service/stock" />
</volume>
</xsl:template>
<xsl:template match="stock[@name = 'e-exchange']">
<xsl:variable name="chance" select="." />
<xsl:variable name="tok_l" select="tokenize($chance, '\n')" />
<xsl:for-each select="$tok_l">
<xsl:variable select="tokenize(., '\s{2,}')" name="values" />
<country name="{$values[5]}">
<transit><xsl:value-of select="$values[10]"/></transit>
<connection><xsl:value-of select="$values[11]"/></connection>
</country>
</xsl:for-each>
</xsl:template>
</xsl:stylesheet>
Explanation
We have parsed a long string in an XML file, and the fields are segregated like column 1 to column 11. We are required to print the result with the new elements. Therefore we use powerful tokenize() in several ways in a code, like using it in variable XSL, taking each line in a for-each loop, and assigning a tokenized string into a value [no] referencing an index.
Output:
This Outputs the XML
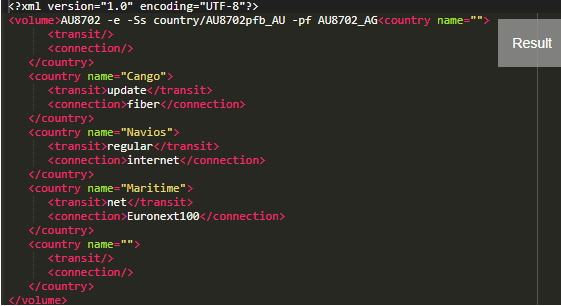
Example #3
XML
<?xml version="1.0" encoding="UTF-8" ?>
<Community>
<Boosters>Work Day , programs, events</Boosters>
<Forums> Discussion , Topics,feedback</Forums>
<Usersgroup> inter,extern</Usersgroup>
</Community>
XSL
<?xml version="1.0" encoding="UTF-8"?>
<xsl:stylesheet version="2.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="Community">
<Head>
<xsl:variable name="Boosters" select="Boosters" />
<xsl:for-each select="tokenize($Boosters, ',')">
<new1>
<xsl:value-of select="." />
</new1>
</xsl:for-each>
<xsl:variable name="Forums" select="Forums" />
<xsl:for-each select="tokenize($Forums, ',')">
<old>
<xsl:value-of select="." />
</old>
</xsl:for-each>
</Head>
</xsl:template>
</xsl:stylesheet>
Explanation
The code above is structured by splitting commas and delimiters from the source file and produces a code without commas.
Output:
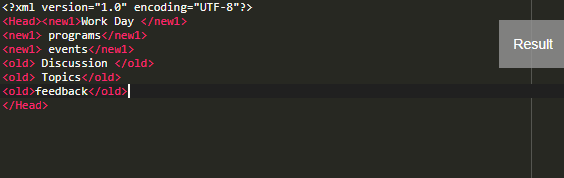
Example #4
XML file for the watch element
<?xml version="1.0" encoding="UTF-8"?>
<Product>
<Watches>
:12:WT67895672333309
Titan:Men
Strap04:525854112,10
</Watches>
</Product>
XSLT file
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet version="2.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<html>
<body>
<h3>Tokenizer String</h3>
<xsl:variable name="paragraph" select="'this is a watch description'" />
The Description: '
<xsl:value-of select="$paragraph" />
' follows
<xsl:value-of
select="count(tokenize($paragraph, '\s+'))" />
few words.
<br />
</body>
</html>
</xsl:template></xsl:stylesheet>
Explanation
This stylesheet counts the tokens available in the input file. And it is numbered ‘5’. The output is shown as follows:
Output:
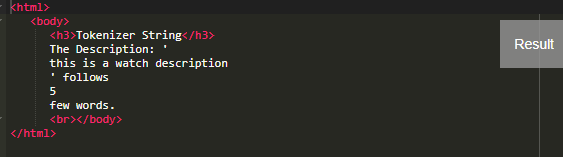
Example #5
XML
<Patients>
<field pname="id">01,12,13</field>
<field pname="name">gia,bob,carl</field>
</Patients>
XSL
<?xml version="1.0" encoding="utf-8"?>
<xsl:stylesheet version="2.0" xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:output indent="yes" method="xml"/>
<xsl:strip-space elements="*"/>
<xsl:template match="/Patients">
<xsl:copy>
<xsl:apply-templates/>
</xsl:copy>
</xsl:template>
<xsl:template match="field[@pname='id']">
<xsl:variable name="match" select="."/>
<xsl:for-each select="tokenize(.,',')">
<xsl:variable name="xxx" select="position()"/>
<Patients>
<id>
<xsl:value-of select="."/>
</id>
<pname>
<xsl:value-of select="tokenize($match/following-sibling::field[@pname='name'],',')[position() = $xxx]"/>
</pname>
</Patients>
</xsl:for-each>
</xsl:template>
<xsl:template match="text()"/>
</xsl:stylesheet>
Explanation
In the stylesheet code, the expression relies on the context where the attribute’s value is retrieved, and each element is tokenized into an individual element.
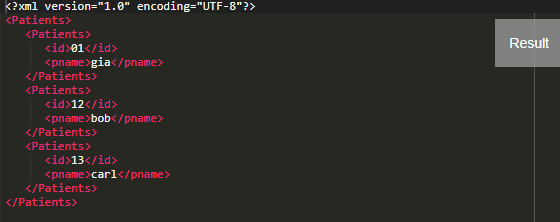
Output:
Conclusion
Therefore, we have seen how to create an XSLT stylesheet for the tokenize function in this article. With a simple example, we have divided a comma-delimited string from the source document into individual elements. This makes things easier when it requires comma eliminations.
Recommended Articles
This is a guide to XSLT Tokenizes. Here we discuss the definition, syntax, and parameters. How does the tokenized function work in XSLT? Examples with code implementation. You may also have a look at the following articles to learn more –
